A Brief Discussion on SQL Server Date/Time Queries and Precision Rounding Pitfalls
I actually wanted to write this article a while ago, but I decided to shelve it at the time. To be honest, I didn't like taking notes when I was a student; if I lost focus for even a second in class, I wouldn't know where the lecture went or how to catch up, so I preferred reading books on my own (whether I actually understood or learned anything is another story...). Later, when I started working, I gradually began writing notes for others to read. However, those early notes were either lost or, upon looking back, felt outdated or even became "dark history," with only a few being migrated here to fill up the post count.
In the process of writing notes for others, there is less room for ambiguity, so I end up checking more materials to verify facts and organize my thoughts. I later discovered that this process allows me to iteratively update my "mental model" (a term I learned recently when AI helped me calibrate my vocabulary).
Currently, my notes can be roughly divided into three categories:
- Tutorials or Best Practices: Instructional articles written specifically for certain people. Usually, when I see incorrect practices or missing fundamental knowledge, I write to explain the standard approach, why it should be done that way, and the underlying principles (though for some details, I might only truly clarify them while writing).
- Contextual Records and Verification: Records of problem-solving processes in specific scenarios, verification attempts of certain ideas, or records that I've studied but are now outdated yet still kept.
- Learning Notes: Byproducts of learning new technologies or unfamiliar fields.
In the second half of last year, I didn't want to touch code for about 2–3 months. It wasn't until later that I started writing while researching new things, and during this time, I often wondered if I should continue writing at all.
During that period, I would frequently feed my notes to Gemini, Claude, and ChatGPT, asking them if my notes were poorly written or if spending so much time on them was meaningless.
Even for parts I am familiar with and already know, even with AI assistance, actually writing them out takes several hours, sometimes even days.
Although I write for fun and update whenever I feel like it, seeing technical blogs like Darkthread or Bill Chung that are frequently searched, their update frequency and article depth make me feel like my writing is somewhat meaningless. Some of my practices are even called "non-standard" by AI (though I consider them relatively standard among "wild" methods), and then I often disappear for months when I get busy.
Gemini and the others also gave feedback, saying that the structure of my "notes written for others" might not be suitable for the intended audience. The supplementary fundamental knowledge might have too high an information density, leading to confusion or even resistance to reading.
And for those notes that "correct existing practices or concepts," I need to ensure the accuracy of the knowledge—after all, I never feel my understanding is absolutely correct—so I have to spend time checking data and testing. After all, the literary disdain among engineers is quite severe, and it often involves "holy wars."
But this leads to a paradoxical situation: to substantiate my claims, I include test records; but when notes are full of information, some people don't want to see it; they just want to see "how to solve it" or "how to write it" so they can apply it directly.
ChatGPT also mentioned that for an AI, my paragraph logic is clear, but for some readers, the transitions between paragraphs are lacking, and they might not know why I suddenly jumped to another topic.
However, I am resistant to improving this. Writing this way has become a habit, and I've even written some parts with a sense of weariness; if I have to spend effort handling those transitions, then forget it.
Also, I don't know when it started, but sometimes I use the background context as a diary, just rambling on.
Anyway, I already started not wanting to write the first category of tutorial notes anymore. I'll just keep the knowledge gaps and corrections to myself. After chatting with AI, I want to write them even less, so I've decided to treat notes simply as a byproduct of learning.
However, a few days ago, I encountered a strange scenario in an Oracle 11g environment, so I thought I might as well write this article.
SQL Server Date/Time Types
The parts involving SQL Server below are based on SQL Server 2025.
In SQL Server, the common date/time types and their corresponding current time functions are shown in the table below:
| Type | Range | Precision | Current Time Function | Description |
|---|---|---|---|---|
| datetime | 1753-01-01 ~ 9999-12-31 | 3.33 ms (0.00333s), rounds up | GETDATE() | Legacy system product. Milliseconds are not continuous; they round to .000, .003, .007. |
| smalldatetime | 1900-01-01 ~ 2079-06-06 | 1 minute | GETDATE() | Rarely used. Seconds are "rounded" to the minute (29.998s rounded down, 29.999s rounded up). |
| datetime2 | 0001-01-01 ~ 9999-12-31 | 100 ns (customizable 0~7 decimals) | SYSDATETIME() | First choice for new projects. Higher precision and wider range; default precision is 7 (100ns). |
| datetimeoffset | 0001-01-01 ~ 9999-12-31 | 100 ns (customizable 0~7 decimals) | SYSDATETIMEOFFSET() | Includes time zone offset (+14:00 to -14:00), suitable for international applications. |
TIP
In practice, I only recommend using datetime2 and datetimeoffset (if time zone requirements exist).
The range of smalldatetime is too small (it expires in the year 2079). While that seems far away, there's no guarantee it won't become the next "Y2K" trap. Since datetime has a superior successor in datetime2, there is no reason to look back. Furthermore, when migrating from Oracle to SQL Server, one often encounters Oracle data containing dates earlier than 1753. Using datetime will cause write failures, which is another important reason to choose datetime2 (which supports dates down to 0001).
Choosing Precision: (0), (3), (7)
Both datetime2 and datetimeoffset allow setting time precision from 0 to 7 (e.g., datetime2(3)). Although customizable, the following three are more common in practice:
Precision
(0)- Seconds:- Scenario: No high-precision display requirements, or creation times for non-high-concurrency systems.
- Consideration: Often, the UI only displays up to "seconds." If the database stores "milliseconds," users querying based on the UI time won't find the data. Setting it to
(0)avoids this inconsistency between frontend display and backend storage.
Precision
(3)- Milliseconds:- Scenario: Industry standard, default precision for most programming languages (e.g., JavaScript
Date). - Consideration: Balances performance and sufficient resolution. In high-concurrency scenarios, it provides basic execution order judgment.
- Scenario: Industry standard, default precision for most programming languages (e.g., JavaScript
Precision
(7)- 100 Nanoseconds (Default):- Scenario: Extremely high-precision scientific computing or system logging.
- Consideration: Consistent with C#
DateTime.Ticksprecision. However, be aware of whether the hardware clock can actually support this resolution; otherwise, you're just storing a bunch of meaningless trailing digits.
WARNING
The default precision (7) mentioned here refers to the default definition of the datetime2 type in SQL Server.
If created via Entity Framework Code First, the default behavior may vary depending on the version or Provider if the precision is not explicitly specified. It is strongly recommended not to rely on the framework's defaults and to explicitly specify the precision (e.g., .HasPrecision(0)) to avoid unexpected behavior during future upgrades or migrations.
The Dilemma of Precision and Consistency
When pursuing extremely high precision (like precision 7), you first need to solve a prerequisite: the consistency of the time source.
Suppose your application needs to record the "current" time point in multiple places:
- Does each place call
DateTime.Nowindividually? - Or is it obtained once from a single source and passed to where it's needed?
- Or do you let the database fill it in automatically via
DEFAULT GETDATE()or aTrigger?
At low precision (e.g., 0 or 3), these differences might not be obvious. But when precision is increased to 7 (100 nanoseconds), the tiny time differences between each call to DateTime.Now are amplified, leading to inconsistencies in timestamps for different columns in the same transaction.
So, when choosing high precision, you might need to decide how time should be generated:
- Generate it once at the application layer and pass it to all required places?
- Or let the database layer generate it automatically (but the application layer won't know the time before
SaveChanges)? - In a distributed environment, how do you handle clock drift between different servers?
This isn't just a question of how finely the database can store data; it's about how much control your application architecture has. Without predefined standards, high precision might expose more inconsistencies.
Choosing the Time Source: Application Layer vs. Database Layer
TIP
The following explanation uses DateTime.Now corresponding to GETDATE() as an example, but the same concept applies to DateTime.UtcNow (corresponding to GETUTCDATE()) or DateTimeOffset.Now (corresponding to SYSDATETIMEOFFSET()).
In Entity Framework, one thing to note is that the SQL syntax generated by the following two approaches is actually quite different.
// Approach A: Using DateTime.Now directly in LINQ; depending on the Provider implementation, it might be translated to GETDATE()
db.Table.Where(x => x.RecordTime == DateTime.Now);
// Approach B: Storing DateTime.Now in a variable and passing it as a parameter
DateTime now = DateTime.Now;
db.Table.Where(x => x.RecordTime == now);I used to advise colleagues at work to write the latter (Approach B). There are several considerations for this:
First, in a non-distributed architecture, I prefer to centralize time processing at the application layer rather than the database layer. This avoids the issue of time desynchronization between the application server and the database server.
Although theoretically, environments should be synchronized, I have indeed encountered situations where the two sides were out of sync. Of course, I wouldn't mock such a situation; given my lack of knowledge in Infrastructure, if it happened, I might not be able to handle it either.
Second, if time calculations are involved, it's best to finish the calculation at the application layer. Although if the column has an Index, theoretically RecordTime = @d, RecordTime = GETDATE(), or RecordTime = DATEADD(MINUTE, 1, GETDATE()) should all utilize the Index.
However, with complex calculations, the resulting SQL can have some uncertainty. Early Entity Framework 6 Expressions were prone to issues with date handling; while Entity Framework Core has better support now, there have been cases where "it could generate SQL, but then it was decided that performance was poor, and support was dropped in a certain version," leading to errors.
As for performance considerations, as long as the Index is utilized, there shouldn't be a huge difference. The actual result might depend on statistics, execution plans, and the match between query parameter values.
WARNING
In SQL Server, performing operations on a column (e.g., DATEADD(MINUTE, -1, RecordTime) = GETDATE()) causes SARGability (Search ARGument ABility) to fail, causing an Index Seek to degrade into an Index Scan.
I mentioned trying to handle time at the application layer; besides the EF considerations above, the main reason I'm writing this is a special case I encountered in Oracle 11g.
I previously saw a query condition:
RecordDate >= (TO_NUMBER(TO_CHAR(SYSDATE, 'YYYYMMDD')) - 19110000) OR RecordDate = 0;Strangely, RecordDate did have values of 0, and it was connected with OR, so it should have been able to retrieve those 0 values, but it didn't.
Then I changed it to the following, and it worked:
RecordDate = 0 OR RecordDate >= (TO_NUMBER(TO_CHAR(SYSDATE, 'YYYYMMDD')) - 19110000);
-- Or hardcoding the value
RecordDate = 0 OR RecordDate >= 1150212;Of course, newer versions of the database might have improved this (presumably...), but while rare these days, there are still old projects alive. If you can handle it in the code, try to do so; it can reduce the occurrence of such situations.
Handling Time Range Closure
When I see colleagues write this during Code Review, I usually suggest changing it:
// ❌ Not recommended
DateTime endTime = input.EndTime.AddTicks(-1);
db.Table.Where(x => x.Time >= input.StartTime && x.Time <= endTime);I suggest changing it to:
// ✅ Recommended
db.Table.Where(x => x.Time >= input.StartTime && x.Time < input.EndTime);There are three main considerations for this suggestion:
- Semantically clearer.
- More general: Using
>=and<works fordate,time, andDateTime. If you really need to include the end time, just change the comparison operator. - Precision issues: In most cases, you might not use precision
(7). Especially since some company projects usedatetimeinstead ofdatetime2. ButAddTicks(-1)operates on 100 nanoseconds (precision7). When the precision on both sides is different, my intuition tells me there will be problems.
However, I didn't research it that deeply at the time, and Claude didn't point out the problem either, so I couldn't just say there was a problem based on intuition and force them to change it (though now AI can clearly state there is a problem).
After I had time to verify it, I just let it go.
After all, as I said earlier, I wouldn't write it that way myself; if I did, it was mostly due to complex business logic and being constrained by the project architecture at the time.
Time Precision Issues
Although SQL Server's datetime goes down to milliseconds, its last digit will only ever be 0, 3, or 7.
What kind of precision problem does this cause? The simplest test is to create a table and store time as datetime:
CREATE TABLE Test (
ID INT IDENTITY(1,1) PRIMARY KEY,
RecordTime DATETIME -- Note: this is DATETIME
);
CREATE INDEX IX_Test_RecordTime ON Test(RecordTime);
-- Insert a "sharp" time
INSERT INTO Test (RecordTime) VALUES ('2026-02-10 08:00:00.000');Then query with the following SQL:
-- Declare a time that is only 1ms off
DECLARE @d DATETIME = '2026-02-10 07:59:59.999';
SELECT * FROM Test WHERE RecordTime = @d;The times are different, so it shouldn't return anything, right? But the actual result is that this record will be retrieved. Because of the datetime precision issue, it rounds '2026-02-10 07:59:59.999' up to '2026-02-10 08:00:00.000'.
Of course, if you declare it as datetime2, this problem won't occur. But if the database type is datetime and the variable type is datetime2 (C#'s DateTime is usually treated as high precision when passed), this will cause performance issues.
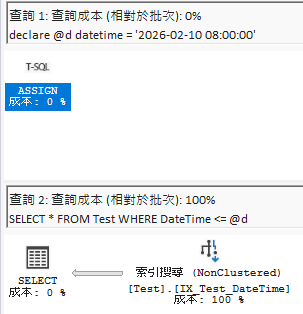
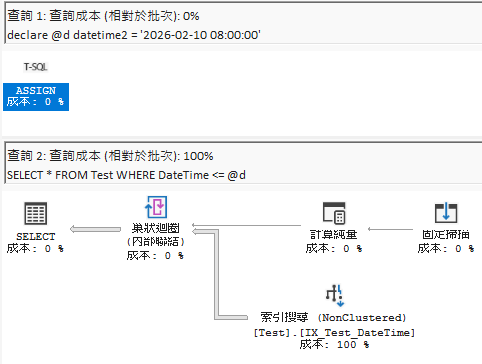
I did a quick test here; the execution plans for = look no different (SQL Server has special optimizations), but when running <=, the difference is obvious even to someone like me who doesn't understand execution plans.
Below is the comparison of execution plans for datetime2 parameters querying datetime columns:
When using = for comparison (both execution plans are the same, SQL Server has optimizations):
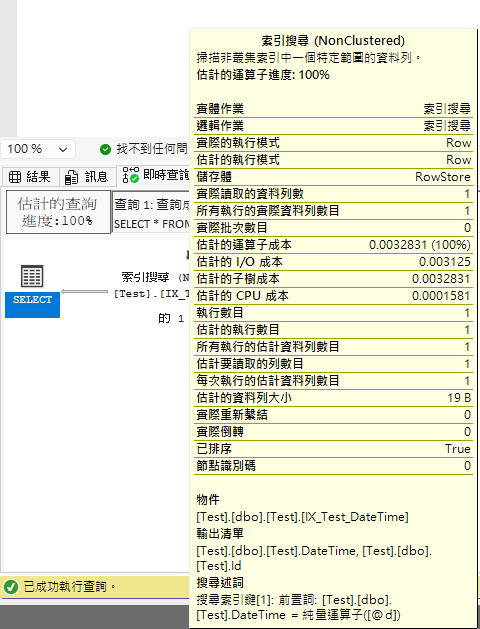
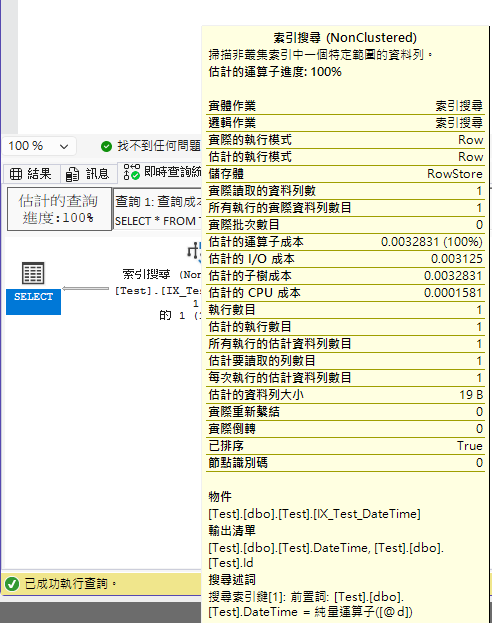
When using <= for comparison (you can see a clear difference):
However, unless you are manually maintaining SQL, whether it's Code First or reverse engineering, type mismatches shouldn't occur; this is more common when using Dapper or ADO.NET.
Of course, if you think using datetime2(7) for the database type will avoid this, I can only say you'll still hit traps in certain scenarios.
If ADO.NET doesn't have the Parameter type specifically set, DateTime defaults to datetime. This leads to the situation of "declaring a datetime variable to query datetime2(7)": the same value, but the variable side rounds up, while the database has the original value, so it can't be found.
As Darkthread's SQL DateTime Type Pitfalls article shows, there is a test result, but what he said in the article:
The reason is likely that Dapper handles @d as SQL DateTime type instead of DateTime2 during INSERT and WHERE, causing errors in the round-trip process.
A more accurate statement is that Dapper relies on ADO.NET at the bottom, so essentially it's the ADO.NET type inference mechanism that causes it.
In other words, when using Entity Framework, unless the time precision is set to (7), this AddTicks(-1) approach will only cause misjudgments when using <= (including unexpected data from the next second).
If you aren't using Entity Framework and you don't set the Type, it's just as easy to run into problems. So the conclusion is: Just be obedient and use < (less than) for range queries.
Change Log
- 2026-02-12 Initial document creation.