SQL Server 效能調教
使用 SSMS 執行計畫工具分析和最佳化查詢
SQL Server Management Studio (SSMS) 提供了執行計畫工具,可用於分析和最佳化查詢的效能。這個工具有兩種模式,包含「包括實際評估計畫」和「顯示估計執行計畫」,它們在以下幾個方面有所不同:
包括實際評估計畫。
- 顯示實際查詢執行時的計畫。
- 提供實際的執行統計資訊,例如查詢花費的時間、讀取的資料量等。
- 通常用於調整和最佳化已經執行過的查詢,以了解實際執行的效能瓶頸。
顯示估計執行計畫。
- 顯示查詢最佳化器根據統計資料所做的預估計畫。
- 提供估計的執行統計資訊,例如預估的行數、預估的資料讀取量等。
- 通常用於分析未執行的查詢,以及檢查查詢的效能瓶頸。
在調整查詢的效能時,可以按照以下步驟進行:
- 顯示估計執行計畫」來分析查詢,特別是對於執行時間較長的查詢,可以在執行查詢之前產生計畫結果,從中了解查詢的預估效能和瓶頸所在。
- 根據現有的效能問題,您可以考慮補上遺漏的索引或進行其他調整。
- 包括實際評估計畫」重新執行查詢,以取得實際的執行統計資訊,並驗證調整後的效果。
下面是使用 SSMS 執行計畫工具的操作範例:
包括實際評估計畫
- 包括實際評估計畫」使之反白。
- 點擊「執行」來執行查詢語法。
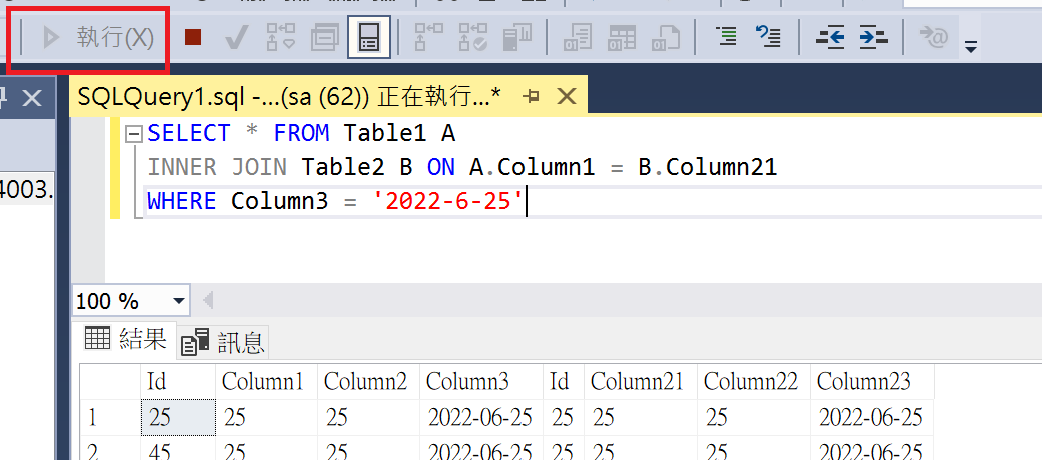
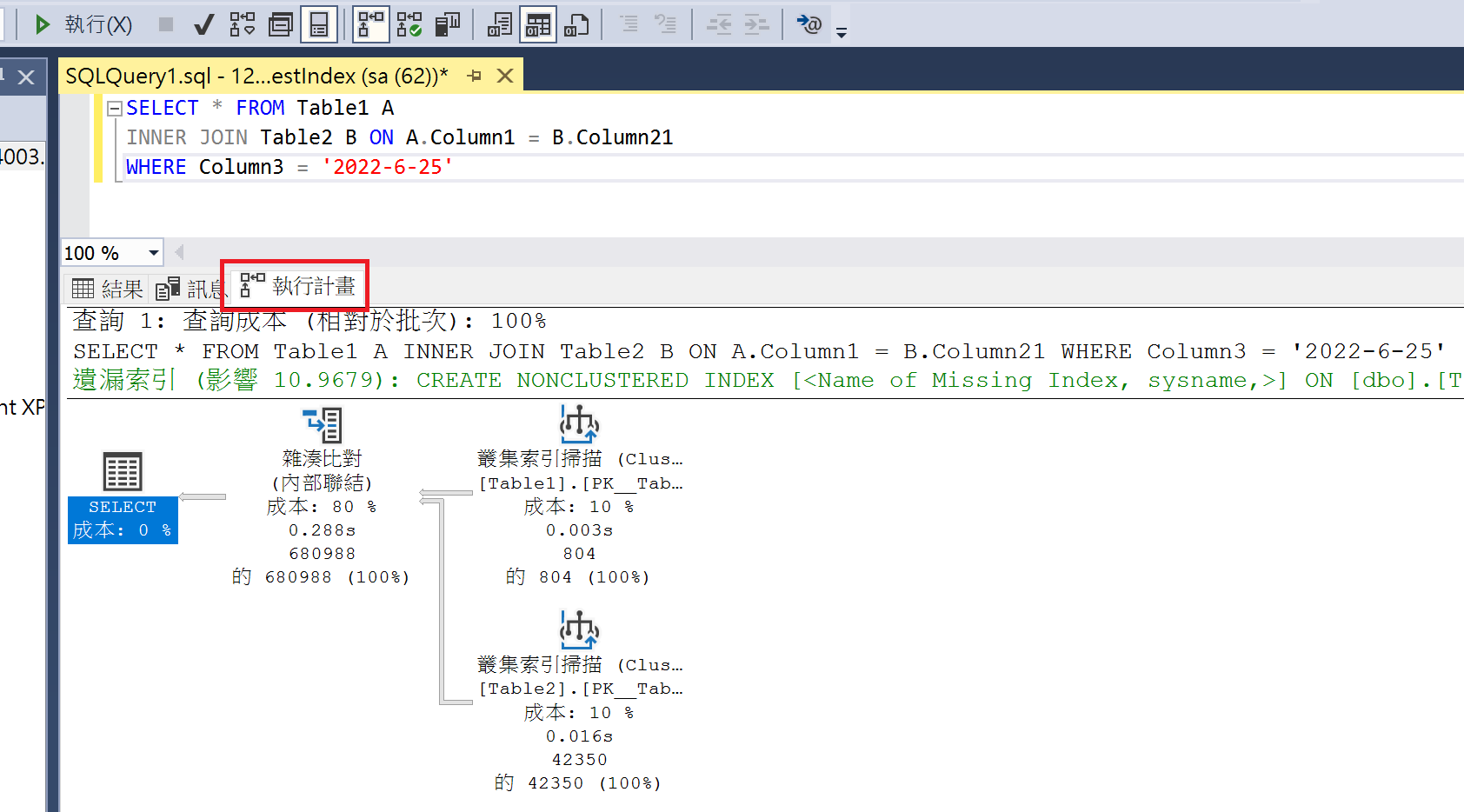
- 查詢完畢後,可以發現額外增加一個「執行計畫」的頁籤,裡面會顯示執行計畫內容,如果有缺漏索引,會有相應的提醒。
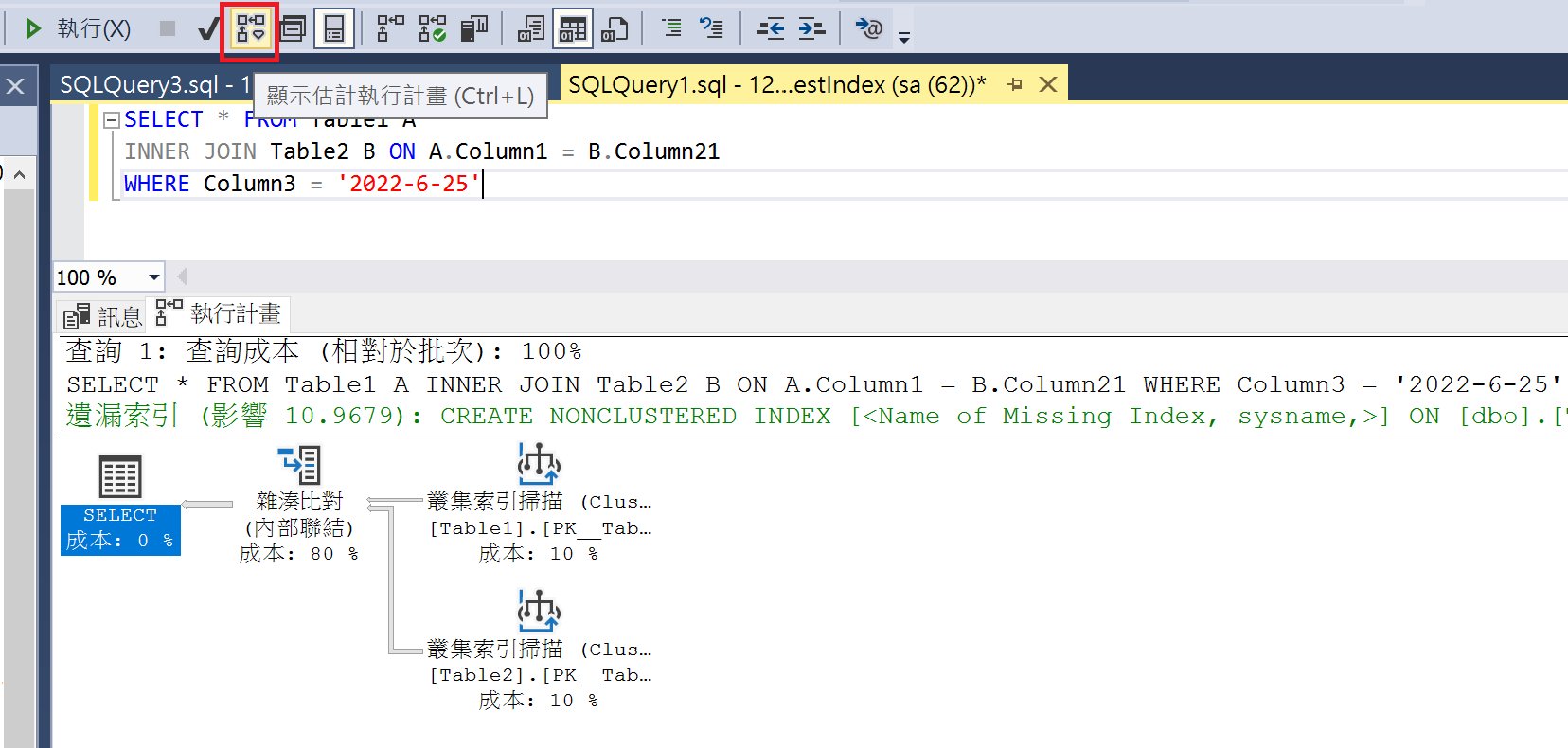
顯示估計執行計畫
如果點擊「顯示估計執行計畫」,不需要點擊「執行」,會直接顯示「執行計畫」,由於沒有真正執行查詢,所以不會有「結果」頁籤顯示。
補上遺漏的索引
- 對「執行計畫」按右鍵,選擇「遺漏索引詳細資訊」。
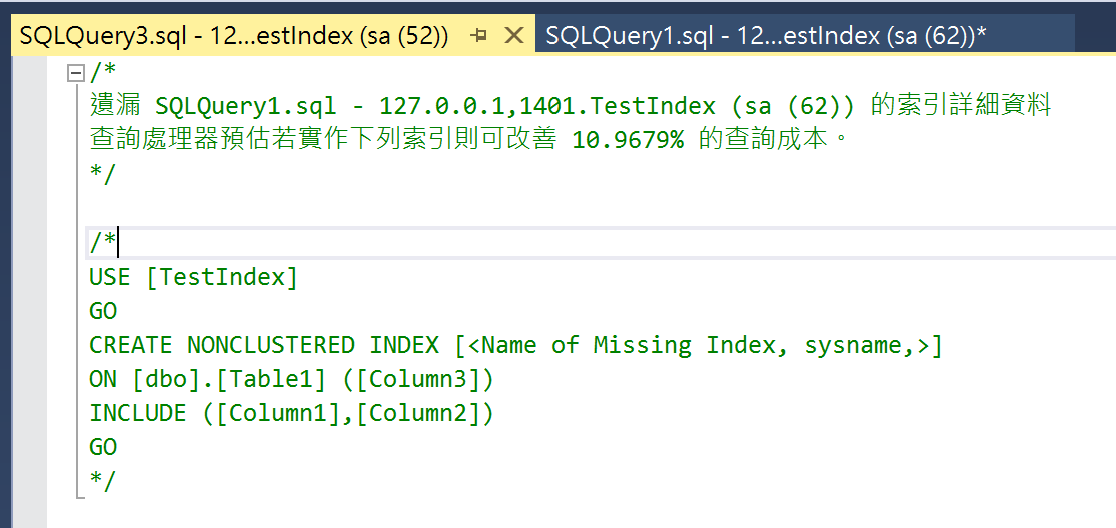
- 產生包含建立索引語法的視窗,可以使用該語法來補上遺漏的索引。
如果想從 Dynamic Management Views 裡儲存的執行計劃來找出遺漏的索引,可使用以下語法查詢,並組合建立索引的語法:
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;WARNING
請勿只是單純根據遺漏的索引來建立索引,許多索引是可以整合的。過多的索引反而可能降低寫入效能。
參考資料
SQL Server 索引簡介
這裡僅對 SQL Server 的索引進行簡單的說明,因為較為複雜的部分我也不太瞭解。
SQL Server 中的索引是基於 B-Tree(平衡樹)結構實現的,它以鍵值(key)和指向對應資料的指標組成。索引可以根據鍵值的排序方式分為兩種類型:叢集索引(Clustered Index)和非叢集索引(Non-Clustered Index)。
- 叢集索引:
- 決定資料的物理排序方式。
- 每個資料表只能有一個叢集索引,且索引鍵的值唯一。
- 若資料表已有叢集索引,新建立的索引將成為非叢集索引。
- 叢集索引適合使用連續性較高的資料,像是 GUID 不適合作為叢集索引,因此有時會使用流水號欄位作為叢集索引的鍵值。
- 非叢集索引:
- 在叢集索引上建立的二級索引。
- 包含索引鍵和指向叢集索引中對應資料的指標。
- 資料表可以有多個非叢集索引,且索引鍵的值可以重複。
TIP
依據我的習慣,我會使用以下命名規則: 主鍵:PK_TableName。 叢集索引:CX_TableName_Column1_Column2。 非叢集索引:IX_TableName_Column1_Column2。
以下是建立非叢集索引的語法,中括號內的部分是可選的:
CREATE INDEX IndexName ON Schema1.Table1(Column1[,...N]) [INCLUDE(Column2[,...n ])];INCLUDE 用途
使用 INCLUDE 子句可以在非叢集索引中包含非鍵欄位的資料,以提高查詢效能。通常,索引只包含索引鍵欄位,而其他非鍵欄位需要從資料頁面中讀取。通過使用 INCLUDE,可以直接將非鍵欄位包含在索引中,減少從資料頁面讀取的操作,從而提高查詢效率。
舉例來說,如果有以下索引:
CREATE NONCLUSTERED INDEX IX_Table1_Column1_Column2 ON [dbo].[Table1] ([Column1], [Column2]) INCLUDE ([Column3])當查詢語句如下時,Column1 和 Column3 可以從索引中讀取資料,而 Column4 需要從資料頁面讀取:
SELECT Column1, Column3, Column4 FROM Table1 WHERE Column1 = 'Value'複合索引的左前綴規則(Leftmost Prefix Rule)
複合索引在查詢時遵循左前綴規則,只有在查詢條件中使用的欄位與索引的最左邊連續欄位相符時,索引才能有效地支援該查詢條件,並提供最佳效能。
假設有一個包含三個欄位(Column1、Column2 和 Column3)的索引,按照 Column1、Column2 和 Column3 的順序建立索引。根據最左前綴規則,當只使用 Column1 和 Column2 欄位作為查詢條件時,索引的最左邊欄位 Column1 和接下來的欄位 Column2 都可以被利用,而不需要進一步的掃描。然而,如果查詢條件使用 Column1 和 Column3 欄位,索引只能利用最左邊的欄位 Column1,Column3 欄位則無法被有效地利用。如果查詢條件使用 Column2 和 Column3 欄位,整個索引都無法被有效運用。
TIP
需要注意的是,當查詢條件中的欄位不符合最左前綴規則時,不同的資料庫或版本可能對於索引的使用情況有所不同。在 SQL Server 中,根據目前官方文件的說法,查詢最佳化器是不會使用該索引。
Consider the order of the columns if the index contains multiple columns. The column that is used in the WHERE clause in an equal to (=), greater than (>), less than (<), or BETWEEN search condition, or participates in a join, should be placed first. Additional columns should be ordered based on their level of distinctness, that is, from the most distinct to the least distinct.
For example, if the index is defined as LastName, FirstName the index will be useful when the search criterion is WHERE LastName = 'Smith' or WHERE LastName = Smith AND FirstName LIKE 'J%'. However, the query optimizer wouldn't use the index for a query that searched only on FirstName (WHERE FirstName = 'Jane').
然而,在 MySQL 8.0.13 中,引入了名為「Index Skip Scan」的功能,它在某些情況下仍可使用不符合最左前綴規則的索引。
另外,對於左前綴規則,它指的是索引的欄位順序,而與查詢條件中的欄位順序無關。
查詢遇到鎖定資料的處理方式
當查詢遇到資料鎖定時,可以選擇以下方式來處理:
NoLock
使用 NoLock 可以指示 SQL Server 在執行查詢時忽略資料的鎖定,直接讀取被鎖定的資料。然而,這可能導致讀取到正在被其他交易修改的資料,或者讀取到未提交的交易所做的更改,進而產生不正確或不一致的查詢結果。以下是 NoLock 的使用範例:
SELECT *
FROM TableName WITH (NOLOCK)
WHERE Condition;NoWait
使用 NoWait 可以指示 SQL Server 在執行查詢時不要等待鎖定資源的釋放,而是立即返回錯誤訊息。這可用於避免查詢長時間阻塞,但也可能導致查詢失敗。以下是 NoWait 的使用範例:
SELECT *
FROM TableName WITH (NOWAIT)
WHERE Condition;ReadPast
使用 ReadPast 可以指示 SQL Server 在讀取資料時跳過已被其他交易鎖定的資料,只讀取可用的資料。這可用於避免與其他交易的阻塞,但也可能導致某些資料無法被讀取到。以下是 ReadPast 的使用範例:
SELECT *
FROM TableName WITH (READPAST)
WHERE Condition;Parameter Sniffing
Parameter Sniffing 是一個資料庫管理系統在執行查詢時,根據查詢的參數值選擇執行計劃的過程。然而,這可能導致問題,當第一次執行的查詢使用一組特定的參數值生成了執行計劃,但該計劃可能在後續查詢中不再適用。
具體來說,如果第一次執行的查詢使用了極端的參數值,資料庫管理系統可能根據這些值生成了一個特定的執行計劃,並將其儲存。然而,當後續查詢使用不同的參數值時,先前的執行計劃可能不再是最佳選擇,導致查詢效能下降。
Parameter Sniffing 的效能問題辨識
當使用參數化查詢時,若觀察到以下情況,很可能是受到 Parameter Sniffing 的影響,導致查詢效能變得緩慢:
- 使用參數化查詢時,查詢執行時間較長。
- 改為非參數化查詢後,相同的查詢時間恢復正常。
以下是一個範例語句:
DECLARE @Name VARCHAR(50) = 'Wing';
-- 參數化查詢
SELECT * FROM TableName Column = @Name;
-- 非參數化查詢
SELECT * FROM TableName Column = 'Wing';解決方法
查詢存放區 (Query Store):
這是 SQL Server 2016 以後版本建議採用的方案。它會持續收集查詢的執行計畫與效能數據。當我們在 SSMS 的圖形化報表(如「迴歸查詢 (Regressed Queries)」)中發現某個查詢的計畫出現分岔 (Plan Regression),導致效能忽快忽慢時,可以直接使用「強制計劃 (Force Plan)」功能,將效能穩定的計畫固定下來。
WARNING
- SQL Server 2022 (16.x):新建立的資料庫將預設開啟 Query Store (詳見 官方部落格)。
- 若在舊版本手動開啟,務必檢查設定值(如
MAX_STORAGE_SIZE_MB與擷取模式QUERY_CAPTURE_MODE),避免因記錄過多 Ad-hoc 查詢而耗盡空間或影響 CPU。
- 若在舊版本手動開啟,務必檢查設定值(如
使用
OPTION (OPTIMIZE FOR):此提示 (Hint) 允許我們引導優化器,針對特定的參數假設來產生計畫:
針對「特定值」 (
@Variable = Value):當資料分佈極度不均,且我們希望優化器針對「最常見」的那個值來產生計畫時使用。這樣可避免優化器剛好「嗅探」到極端少數的參數值,產生了全表掃描等不適用於大多數情況的計畫。
sqlDECLARE @Status INT = 1; -- 強制優化器假設 @Status 為 1 來產生計畫,無視實際傳入的值 SELECT * FROM [Lease] WHERE [Status] = @Status OPTION (OPTIMIZE FOR (@Status = 1));
WARNING
針對大宗值優化可確保系統整體穩定,但對於那些「小眾值」的查詢,可能會因為被迫使用大宗值的計畫(如 Index Scan 而非 Index Seek)而變慢。若資料量巨大,可能需搭配篩選索引 (Filtered Index) 來輔助。
針對「未知值」 (
UNKNOWN): 告訴優化器:「不要相信本次傳入的參數值」,改用欄位的統計分佈平均值來產生計畫。這能產生一個「中庸」且穩定的計畫,避免因參數不同而導致效能劇烈震盪。sqlSELECT * FROM TableName WHERE Condition OPTION (OPTIMIZE FOR UNKNOWN);使用
OPTION (RECOMPILE):指示 SQL Server 在「每次」執行此查詢時,都依照當下的參數值重新編譯計畫。
適用情境:查詢執行頻率低,但參數組合複雜且資料分佈變異極大的報表類查詢。
代價:會增加 CPU 的編譯成本,不適合高併發的 OLTP 查詢。
sqlSELECT * FROM TableName WHERE Condition OPTION (RECOMPILE);
清除執行計畫快取:
這是最傳統的「重置」手段,強制 SQL Server 遺忘舊的(可能是壞的)計畫,下次執行時重新編譯。適合用於緊急排除正式環境的 Parameter Sniffing 阻塞。
sql-- 清除「特定」查詢的計畫 (建議做法,影響最小) DBCC FREEPROCCACHE ({plan_handle}); -- 清除「整個」伺服器的計畫快取 (非必要請勿使用,會導致所有查詢瞬間變慢) DBCC FREEPROCCACHE;如何找出潛在的受害者?
可以使用以下腳本,找出執行時間變異極大(Max/Avg 比率過高)的查詢,這通常是 Parameter Sniffing 的徵兆:
sqlSELECT TOP 20 t.text AS [SQL Text], st.execution_count, [Max Elapsed (ms)] = st.max_elapsed_time / 1000, [Avg Elapsed (ms)] = (st.total_elapsed_time / st.execution_count) / 1000, -- Max/Avg Ratio:若 > 10 代表極度不穩定 (忽快忽慢) [Max/Avg Ratio] = CAST(st.max_elapsed_time * 1.0 / NULLIF(st.total_elapsed_time / st.execution_count, 0) AS DECIMAL(10,2)), st.plan_handle, st.last_execution_time FROM sys.dm_exec_query_stats AS st CROSS APPLY sys.dm_exec_sql_text(st.sql_handle) AS t WHERE t.dbid = DB_ID('{YourDatabaseName}') AND st.execution_count > 50 -- 過濾掉偶發查詢 ORDER BY [Max/Avg Ratio] DESC;
異動歷程
- 2023-03-15 初版文件建立。
- 2026-01-01
- 修正 Parameter Sniffing 檢測腳本中判定邏輯與預期相反的錯誤。
- 增加 Parameter Sniffing 的其他解決方案。