iPAS 備考筆記 - 營運智慧分析師(初級)
考完了兩科 iPAS 證照,看到資訊領域在 115/10/31 還有一個營運智慧分析師證照考試,就想說之後也來考看看,雖然念完後覺得和想像中不太一樣就是…,照慣例將官方提供的兩份講義速讀後,就讓 AI 幫我整理成自己讀得比較習慣的筆記。不過這個科目沒有考古題,沒辦法測試大概能考幾分。加上講義提到的只是基本內容,很多考題在考綱內卻不在講義裡,說實話這樣去考感覺心裡有點不踏實就是。
營運智慧基本知識
營運智慧與商業智慧
商業智慧(Business Intelligence, BI)是企業運用資訊科技,從日常營運資料中整理出有決策價值的資訊,協助企業改善營運績效與競爭力。
營運智慧則是把商業智慧應用在企業營運模式中的動態系統。它不只看歷史報表,也強調快速、即時、整合的資訊流,將研發、採購、生產、行銷、財務、會計、人力資源等流程中的重要資訊與關鍵指標整理成決策依據。
| 概念 | 重點 | 典型用途 |
|---|---|---|
| 商業智慧(BI) | 蒐集、整合、分析與呈現企業資料。 | 報表、儀表板、趨勢分析、KPI 追蹤 |
| 營運智慧 | 將 BI 分析放進企業營運流程,支援即時與多維度決策。 | 生產規劃、銷售分析、財務分析、人資績效 |
| 大數據分析 | 處理結構化、半結構化與非結構化資料,偏資料驅動。 | 社群分析、顧客行為預測、智慧製造 |
營運智慧系統架構
營運智慧系統通常包含三層:資料層、整合層與分析層。資料先由各種營運系統產生,再進入資料倉儲或資料平台整合,最後透過分析引擎與資料呈現工具供決策使用。

| 層次 | 說明 | 常見技術 |
|---|---|---|
| 資料層 | 資料來源與營運系統。 | ERP、CRM、SCM、POS、感測器、外部資料 |
| 整合層 | 將不同來源資料清理、轉換、整合。 | 資料倉儲、ETL、Metadata Repository |
| 分析層 | 分析資料並製作報表。 | OLAP、資料探勘、統計分析、BI 工具 |
KPI 與平衡計分卡
KPI(Key Performance Indicator,關鍵績效指標)是衡量組織是否朝目標前進的指標。營運智慧的工作之一,就是找出部門、流程與整體組織的 KPI,讓管理者可以檢視、衡量與修正行動方案。
平衡計分卡(Balanced Scorecard, BSC)是一種策略管理方法,將願景與策略轉成四個構面的具體指標。
| 構面 | 關注問題 | 範例 KPI |
|---|---|---|
| 財務 | 對股東與財務成果是否有貢獻? | 營收成長率、毛利率、投資報酬率 |
| 顧客 | 顧客如何看待企業? | 顧客滿意度、續約率、客訴率 |
| 內部流程 | 哪些流程必須表現良好? | 交期達成率、良率、流程週期時間 |
| 學習與成長 | 組織是否具備持續改善能力? | 員工訓練時數、技能覆蓋率、創新提案數 |
平衡計分卡的四構面之間具有因果關係。學習與成長為基礎,內部流程改善後帶動顧客滿意度,最終反映於財務成果。這種因果結構稱為策略地圖(Strategy Map)。

營運智慧在企業管理的應用
營運智慧可應用在生產、銷售、財務會計、人力資源等企業功能,重點是把各流程的資料轉成可以支援管理行動的資訊。
| 企業功能 | 營運智慧用途 | 對應系統 |
|---|---|---|
| 生產規劃與控制 | 掌握生產數量、排程、產能、實際與計畫差異。 | ERP、MRP、MES |
| 銷售與配銷分析 | 分析顧客、訂單、通路、促銷與配送資料。 | ERP、CRM、SCM、PLM |
| 財務與會計 | 整合作業流程與財務資料,支援管理會計與財務會計。 | ERP 財會模組 |
| 人力資源 | 量化人力資源績效,追蹤人力運用狀態。 | HRIS、BI 儀表板 |
以銷售與配銷為例,這個流程常同時牽動多個系統,可看出它們如何分工。
| 系統 | 在銷售與配銷中的角色 |
|---|---|
| ERP | 儲存銷售活動、訂單、交貨、出貨、請款與主檔資料。 |
| CRM | 管理顧客屬性、行銷活動、促銷與通路互動資料。 |
| SCM | 支援銷售預測、配銷網路、存貨、運輸與訂單分配。 |
| PLM | 管理產品狀態、特徵與生命週期資訊,支援行銷與定價。 |
本節提到的各系統,完整定義見後面的 數位化企業常見資訊系統。
評估與規劃營運智慧
導入營運智慧前要先評估它能否解決現行營運問題,或支援未來經營方向。評估後才進入專案規劃,確認企業是否具備足夠的技術與非技術基礎設施。
| 階段 | 工作重點 | 說明 |
|---|---|---|
| 營運面向評估 | 找出欲解決的營運問題。 | 例如降低庫存、改善交期、提升顧客滿意度。 |
| 成本效益評估 | 比較效益與建置成本。 | 效益可包含增加營收、降低成本、提升市場占有率。 |
| 風險評估 | 評估專案風險。 | 技術風險、專案複雜度、組織風險、團隊風險。 |
| 基礎設施評估 | 檢查導入條件。 | 硬體、中介軟體、資料庫、流程、資料、應用系統、詮釋資料。 |
| 專案規劃 | 建立計畫與排程。 | WBS、任務相依性、資源、關鍵路徑、工期。 |
企業價值可用四個方向衡量。
| 問題 | 衡量方向 | 範例 |
|---|---|---|
| Better? | 品質或滿意度是否改善? | 良率提高、顧客滿意度提高 |
| Cheaper? | 成本是否降低? | 開發成本、溝通成本、庫存成本下降 |
| Faster? | 速度是否加快? | 生產效率、新產品上市時間、服務回應速度 |
| Do more? | 能力或範圍是否擴大? | 新客源、市場占有率、系統使用人數 |
甘特圖、PERT 與 CPM
營運智慧專案可用甘特圖、PERT 與 CPM 進行規劃、排程與控制。
| 工具 | 適合用途 | 重點 |
|---|---|---|
| 甘特圖(Gantt Chart) | 簡單專案排程與進度監控。 | 能看活動時間與進度,但不擅長呈現活動相依關係。 |
| 計畫評核術(PERT) | 任務時間不確定時的估算。 | 使用樂觀、最可能、悲觀三種時間估計。 |
| 要徑法(CPM) | 找出專案最短完成時間與關鍵路徑。 | 關鍵路徑上的活動會直接影響專案完成日。 |
PERT 與 CPM 的共同步驟:
- 定義專案並建立工作分解結構。
- 找出所有活動與先後關係。
- 畫出活動網路圖。
- 對每項活動指派時間與成本估計。
- 計算整個網路中最長的時程路徑。
- 利用網路圖協助規劃、排程與控制專案。
PERT 預期時間公式
設樂觀時間
公式本質是加權平均,分子為
變異數則為:
以「AI 客服模型訓練」這項活動為例,工程師估計樂觀 2 天(一切順利)、最可能 5 天(正常進度)、悲觀 14 天(嚴重出錯):
最常發生的雖是 5 天,但悲觀時間長達 14 天,加權後預期時間被拉到 6 天,填進網路圖的就是這個數字。標準差 2 天則是後續風險分析的輸入。但要回答「8 天內完成的把握多大」這種機率問題,不能直接拿單一活動套常態(單一活動工期近似 Beta 分布);標準做法是先沿關鍵路徑把各活動的平均與變異數彙總成整個專案的完工分布,多個活動加總後依中央極限定理趨近常態,再估機率。屆時若專案完工平均 6 天、標準差 2 天,8 天正好是 +1 個標準差,機率約 84%(平均數以下 50%,再加 0 到 +1σ 的 34%,拆解依據見後面的 經驗法則)。
PERT/CPM 網路圖示意

圖中每個節點代表一項活動(A 為開始、F 為結束),箭頭代表活動間的相依關係,被指向的活動必須等所有前置活動完成才能開始;節點上的天數,就是各活動先以 PERT 公式算出的預期時間。把每條路徑的天數加總:
- A→B→D→F 共 2 + 4 = 6 天
- A→C→D→F 共 3 + 4 = 7 天
- A→C→E→F 共 3 + 5 = 8 天
最長的 A→C→E→F 是關鍵路徑(紅色節點)。專案要等所有路徑都完成才算結束,所以總工期由最長路徑決定,為 8 天;CPM 說的「最短完成時間」指的正是這條最長路徑的長度,再怎麼趕也快不過它。
關鍵路徑上的活動沒有寬裕,C 或 E 每延誤一天,總工期就多一天。非關鍵路徑的活動則有浮時(Float)。以 B 為例,D 要等 B 與 C 都完成才能開工,而 D 需要 4 天,最晚第 4 天開工仍能在第 8 天與 E 同步完成,因此 B 最多可延誤 2 天而不影響工期,超過才會把專案往後拖。
基礎資料分析
資料處理鏈
資料要經過一連串處理,才能從原始紀錄變成可用於決策的資訊。典型流程是資料先進入資料庫,再依分析目的整理到資料倉儲,接著透過資料探勘找出模式,最後用視覺化呈現給決策者。

| 階段 | 重點 |
|---|---|
| 資料 | 可被紀錄的資訊,可能是數字、文字、影像或聲音。 |
| 資料庫 | 儲存日常營運資料。 |
| 資料倉儲 | 依分析目的整合多來源資料。 |
| 資料探勘 | 找出關聯、模式、趨勢或預測規則。 |
| 資料視覺化 | 以圖表、儀表板或報表呈現分析結果。 |
資料來源與資料化
資料不一定是數字,任何可被紀錄的資訊都可能成為資料。企業資料來源包含交易資料、顧客資料、供應鏈資料、感測器資料、客服紀錄、社群文字、影像與影音檔等。
資料化(Datafication)是把原本不容易直接量化的現象轉成可分析資料的過程。例如把客服通話轉成文字,再進行情緒分析;把設備震動訊號轉成時間序列,再預測故障。
結構化、半結構化與非結構化資料
| 資料型態 | 特徵 | 範例 | 優點 | 限制 |
|---|---|---|---|---|
| 結構化資料 | 有固定欄位、格式與順序。 | 銷售資料表、會員資料表 | 容易查詢、整併與分析。 | 彈性較低,不符合欄位規則的資料不易存放。 |
| 半結構化資料 | 有欄位概念,但欄位可增減。 | CSV、JSON、XML | 便於交換與擴充。 | 欄位不一定一致,資料治理要求較高。 |
| 非結構化資料 | 無固定欄位或固定格式。 | 圖片、影片、Email、網頁、客服錄音 | 能保存豐富內容。 | 分析前通常需轉換,轉換過程可能流失資訊。 |
資料品質與前處理
資料品質會直接影響分析結果。常見資料品質問題包含缺失值、重複資料、格式不一致、度量衡不一致、欄位定義不一致與異常值。
| 問題 | 說明 | 處理方向 |
|---|---|---|
| 缺失值 | 欄位未填或無法取得。 | 補值、刪除、標記缺失原因。 |
| 重複資料 | 同一個實體被重複紀錄。 | 去重、主鍵比對、合併紀錄。 |
| 格式不一致 | 日期、電話、地址格式混亂。 | 標準化格式。 |
| 度量衡不一致 | 公斤與公克、台幣與美元混用。 | 統一單位並保留轉換規則。 |
| 定義不一致 | 不同部門對同一欄位定義不同。 | 建立資料字典與共同定義。 |
| 異常值 | 超出合理範圍或違反規則。 | 調查原因、修正或保留並標記。 |
資料品質常見涵義:
- 正確性:資料是否反映真實狀態。
- 可靠性:資料來源與產製流程是否可信。
- 一致性:不同系統或欄位間是否定義一致。
- 完整性:必要欄位是否齊全。
- 相關性:資料是否與原訂商業目標相關。
缺失值處理方法
缺失值處理是資料前處理最常見的工作之一,不同方法各有適用情境。
| 方法 | 說明 | 適用情境 |
|---|---|---|
| 整列刪除(Listwise Deletion) | 直接刪除含缺失值的整筆紀錄。 | 缺失比例極低、刪除後不影響樣本代表性。 |
| 配對刪除(Pairwise Deletion) | 僅在用到該欄位時排除該筆,其他分析仍納入。 | 多變數分析、希望保留更多資料。 |
| 均值/中位數補值 | 以該欄位的平均數或中位數填補。 | 數值型欄位,分布近似常態用平均、有偏態用中位數。 |
| 線性插值(Linear Interpolation) | 用缺失點前後的已知值做線性內插填補。 | 時間序列等連續變化的資料,能保留局部趨勢,避免均值補值抹平變化。 |
| 眾數補值 | 以該欄位出現最多的類別填補。 | 類別型欄位。 |
| 迴歸補值 | 用其他欄位建立迴歸模型預測缺失值。 | 缺失欄位與其他欄位有明確關聯。 |
| KNN 補值 | 以最相似的 K 筆紀錄的平均值填補。 | 多欄位特徵明確、樣本足夠。 |
| 多重插補(Multiple Imputation) | 產生多組可能值並合併分析結果。 | 高品質研究、缺失機制複雜。 |
| 保留並標記 | 保留缺失,新增「是否缺失」旗標欄位。 | 缺失本身具有意義(如未填寫亦是資訊)。 |
資料儲存:從資料庫到資料湖倉
| 概念 | 英文 | 特性 |
|---|---|---|
| 資料庫 | Database | 儲存日常營運(OLTP)資料,採高度正規化。 |
| 資料倉儲 | Data Warehouse | 整合多個營運系統的歷史資料,採固定 Schema,供企業層級分析。 |
| 資料超市 | Data Mart | 資料倉儲的子集,聚焦特定部門或主題(如行銷、財務)。 |
| 資料湖 | Data Lake | 以原始格式儲存結構化、半結構化與非結構化資料,分析時才定義 Schema(Schema-on-Read)。 |
| 資料湖倉 | Data Lakehouse | 結合資料倉儲的管理能力與資料湖的彈性,兼具 ACID 交易與多元格式儲存。 |

資料庫 vs 資料倉儲
兩者都存資料,但服務的目的相反:
- 資料庫面向「營運」,存當前即時資料、頻繁寫入,採高度正規化以減少冗餘(對應 OLTP)。
- 資料倉儲面向「分析」,整合多來源的歷史資料、以查詢為主,採反正規化以加快彙總(對應 OLAP)。
資料庫回答「現在的狀態是什麼」,資料倉儲回答「長期下來趨勢如何」。
ETL 與 ELT
資料倉儲的基礎是 ETL(Extract, Transform, Load),也就是從來源系統萃取資料,清理與轉換後載入資料倉儲。
學習指引也用 ECCD 描述資料處理流程:
| 步驟 | 英文 | 說明 |
|---|---|---|
| 萃取 | Extract | 從原始資料來源取出資料。 |
| 清理 | Clean | 確認資料品質,處理缺失、錯誤與不一致。 |
| 一致化 | Conform | 統一各資料來源的定義、格式與維度。 |
| 交付 | Delivery | 將可用資料交付給應用系統或決策者。 |

ETL 系統規劃時要同時考慮需求與架構。
| 類型 | 考量項目 |
|---|---|
| 需求分析 | 業務、法規、品質、安全、整合、時程、備份、交付、技能、資源 |
| 架構設計 | 工具採購或自行開發、批次或串流、排程自動化、異常處理、品質控制、復原與重新啟動、詮釋資料、資料安全 |
ETL 與 ELT 的差異
ETL 與 ELT 由相同三個步驟組成,差別在 Transform 與 Load 的先後,連帶 Transform 在哪裡執行也不同:
| 步驟 | ETL | ELT |
|---|---|---|
| Extract(萃取) | 從來源系統取出原始資料。 | 從來源系統取出原始資料。 |
| Transform(轉換) | 載入前先在外部工具清洗、套用商業規則。 | 載入後才在平台內利用其算力轉換。 |
| Load(載入) | 最後把整理好的乾淨資料寫入資料倉儲。 | 先把原始資料直接寫入資料湖或資料湖倉。 |
- ETL 適合傳統資料倉儲。以財務月結為例,先在外部統一幣別、去除重複交易、補齊缺值,整理乾淨後再載入倉儲。資料品質高,但商業規則一變動就得重跑整段流程。
- ELT 適合資料湖倉與雲端資料平台。以營運分析平台為例,訂單、POS、客服紀錄先全量載入,再依需求分別產出財務彙總、銷售分析、顧客分群等資料集。原始資料保留完整,新的分析需求出現時可回頭重新轉換,不受初次設計限制。
ELT 為何後來興起
- 早期資料庫儲存成本高,且運算與儲存綁在同一台機器,先在外部轉換縮量再載入是當時的必要做法。
- 雲端物件儲存成本大幅下降,全量先載入變得可行;現代雲端資料平台讓運算與儲存分離,可按需擴充算力在平台內轉換。
- ETL 的彙總與清洗屬破壞性處理,原始細節一旦聚合就消失;保留原始資料的需求,讓 ELT 在現代平台上成為常見選擇。
OLTP 與 OLAP
OLTP(Online Transaction Processing,線上交易處理)與 OLAP(Online Analytical Processing,線上分析處理)是兩種不同用途的資料庫運作模式。
| 面向 | OLTP | OLAP |
|---|---|---|
| 主要用途 | 處理日常交易(新增、修改、刪除) | 分析與決策支援 |
| 資料量 | 單筆小、總量適中 | 大量歷史資料 |
| 操作型態 | 大量短交易、寫入頻繁 | 少量複雜查詢、讀取為主 |
| 資料結構 | 高度正規化 | 反正規化(星狀、雪花式) |
| 典型系統 | ERP、POS、訂單系統 | 資料倉儲、BI 平台 |
OLAP 五大操作
可以把多維分析想像成操作一顆資料立方體(Data Cube)。假設這顆立方體有時間(年/月/日)、地點(國家/城市)、產品三個維度,每個格子存的是該組合的銷售額。五大操作就是用不同方式檢視這顆立方體。
| 操作 | 英文 | 說明與範例 |
|---|---|---|
| 上鑽 | Roll-up | 沿維度從細層彙總到粗層,如把各城市每日銷售加總成全台每月業績。 |
| 下鑽 | Drill-down | 上鑽的反向,從粗層展開到細層,如從全台業績點進各城市看細節。 |
| 切片 | Slice | 固定單一維度的某個值,取出一個平面,如只看「2026 年」這一層。 |
| 切塊 | Dice | 在多個維度各設限制,取出較小的子立方體,如「2026 年 × 台北 × 手機」。 |
| 旋轉 | Pivot | 不改變資料,只調換維度的呈現方向,如報表欄列互換以換個視角閱讀。 |
三組操作的本質不同。上鑽/下鑽改變資料的細緻度,切片/切塊改變資料的範圍,旋轉只改變呈現角度。
切片、切塊與下鑽的辨異
- 切片 vs 切塊:兩者都在篩資料,差別只在固定幾個維度。切片固定一個維度、取出一個平面(3D 變 2D),切塊固定多個維度、取出一塊子立方體。
- 下鑽 vs 切片:兩者都像在縮小聚焦,但下鑽沿同一維度往下變細(改細緻度),切片篩掉某維度的其他值(改範圍),報表會少一個維度。
星狀模型與雪花式模型
資料倉儲多以維度建模(Dimensional Modeling)組織資料,會把資料拆成兩種表。事實表(Fact Table)放在中央,記錄「發生了什麼」的度量數字,如銷售額、購買數量;維度表(Dimension Table)圍繞四周,記錄這些數字的背景,如何時、何地、購買哪項產品。星狀與雪花式的差別,就在維度表怎麼排列。
| 模型 | 特性 | 取捨 |
|---|---|---|
| 星狀模型(Star Schema) | 中央為事實表,四周為直接連接的維度表,維度屬性攤平在同一張表。 | 結構簡單、JOIN 少、查詢快,但維度表會重複資料。 |
| 雪花式模型(Snowflake Schema) | 把維度表再正規化,將重複屬性拆成多層子維度表。 | 節省儲存、減少冗餘,但 JOIN 變多、查詢較慢。 |
以產品維度為例,星狀模型會把產品名稱、分類、分類負責人全放在同一張產品維度表。這裡藏了一層遞移相依,產品決定分類、分類又決定負責人;星狀容忍它,於是 1000 個電子產品就重複寫 1000 次分類與負責人。雪花式則把分類抽成獨立子表、消掉這層遞移相依,等於把維度表推到第三正規化(3NF),代價是查分類名稱要多一次 JOIN。
另外,正規化只動維度表,事實表在兩種模型裡結構都一樣。事實表只放外鍵與度量值(如產品 ID、客戶 ID、數量、金額),沒有描述性文字,也就沒有可拆的遞移相依。
用模擬資料看事實表與維度表
銷售事實表只有外鍵與度量值,沒有任何文字描述:
| 日期 ID | 產品 ID | 客戶 ID | 數量 | 金額 |
|---|---|---|---|---|
| 20260301 | 101 | 501 | 2 | 1000 |
| 20260301 | 102 | 502 | 1 | 30000 |
| 20260302 | 101 | 503 | 5 | 2500 |
星狀模型的產品維度表把描述屬性攤平,分類與負責人會重複:
| 產品 ID | 產品名稱 | 分類 | 分類負責人 |
|---|---|---|---|
| 101 | 藍牙耳機 | 電子產品 | 王小明 |
| 102 | 筆記型電腦 | 電子產品 | 王小明 |
| 103 | 辦公椅 | 家具 | 李大華 |
雪花式則把分類抽成子表,產品表只留分類 ID,「電子產品/王小明」不再重複:
| 產品 ID | 產品名稱 | 分類 ID |
|---|---|---|
| 101 | 藍牙耳機 | C01 |
| 102 | 筆記型電腦 | C01 |
| 103 | 辦公椅 | C02 |
| 分類 ID | 分類 | 分類負責人 |
|---|---|---|
| C01 | 電子產品 | 王小明 |
| C02 | 家具 | 李大華 |
星狀 vs 雪花式:三個取捨面向
星狀與雪花式各擅一邊,實務上從三個面向權衡:
- 查詢速度:星狀 JOIN 少、較快;雪花式 JOIN 多、較慢。
- 儲存空間:星狀容忍重複、較佔空間;雪花式消除冗餘、較省。
- 維護性:雪花式讓重複屬性只存一處,更新改一筆就好;星狀同一份屬性重複多列,更新時得全部改、還可能改漏造成不一致(更新異常)。
不過在資料倉儲,維護性這條的權重比交易型資料庫低,因為倉儲以讀取分析為主、幾乎不改歷史資料,星狀重複帶來的更新負擔不常發生。因此多數情境仍偏好查詢快、SQL 直覺的星狀,儲存成本低廉的雲端平台更強化了這個選擇。
資料視覺化與圖表選擇
資料視覺化的目的,是在不扭曲資料的前提下,用合適的圖表把重點傳達給決策者。
選圖的第一步是先想清楚要表達什麼關係,再挑對應的圖表。
| 分析目的 | 適合圖表 | 說明 |
|---|---|---|
| 比較類別 | 長條圖、橫條圖 | 比較不同類別的數量或大小,類別多時用橫條圖較好讀。 |
| 呈現趨勢 | 折線圖 | 觀察數值隨時間的變化。 |
| 呈現組成比例 | 圓形圖、堆疊長條圖 | 看整體中各部分的占比,類別不宜過多。 |
| 觀察分布 | 直方圖、箱型圖 | 直方圖看連續數值的分布形狀,箱型圖看中位數、四分位數與離群值。 |
| 觀察關聯 | 散佈圖 | 觀察兩個變數之間的關係。 |
| 呈現交叉密度 | 熱力圖 | 以顏色深淺呈現二維交叉的數值高低,如時段 × 區域的銷售熱度。 |
長條圖 vs 直方圖
- 長條圖常用於屬質資料,例如產品類別、地區、部門。
- 直方圖常用於屬量資料,例如金額、身高、工時。
視覺化常見的誤導
同一份資料,畫法不同會給人完全不同的印象,以下是四種常見的誤導手法。
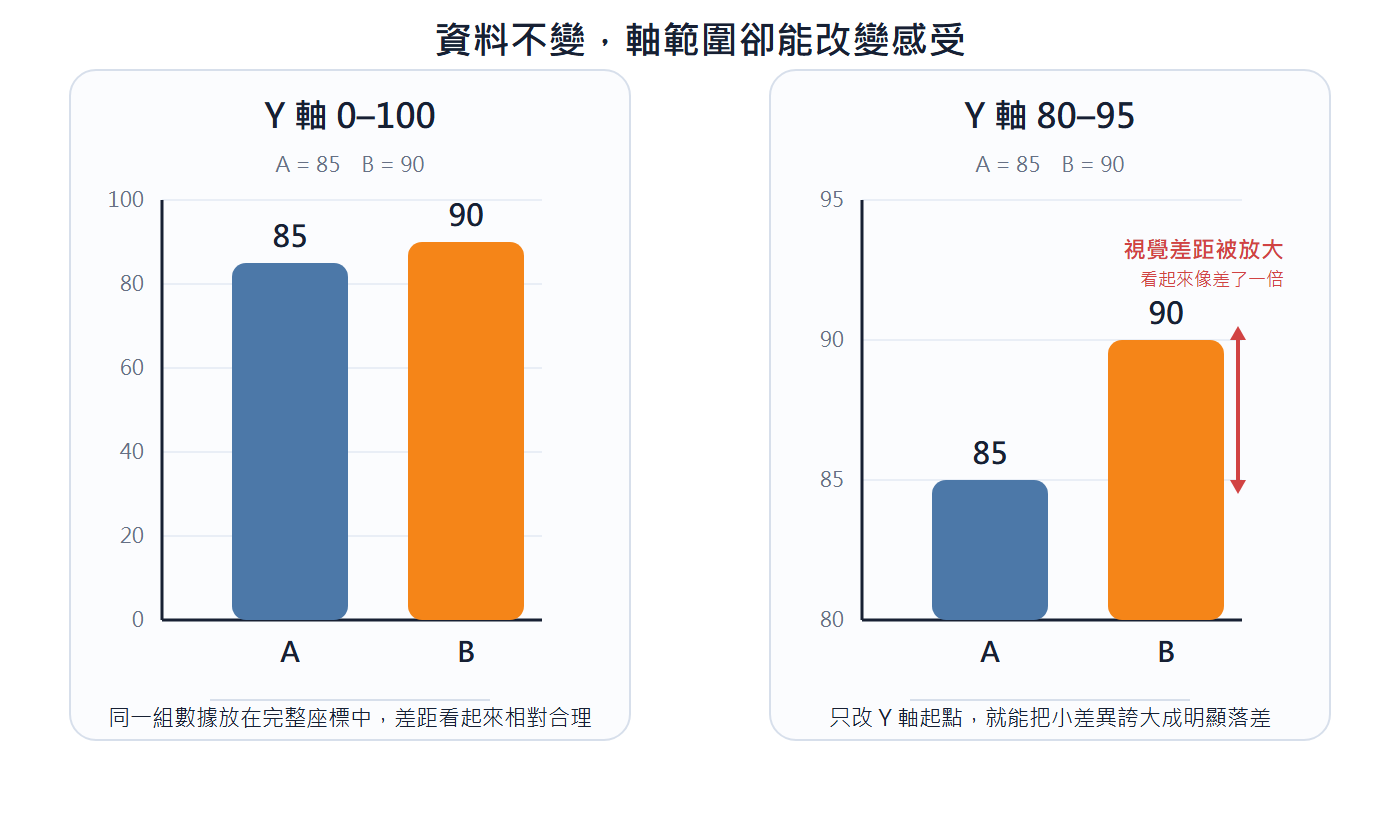
截斷 Y 軸:Y 軸不從零開始,會放大原本微小的差距。例如數值 85 與 90,Y 軸從 0 到 100 時兩根長條幾乎一樣高;改成 85 到 100 後,高度差被嚴重放大,90 看起來遠高於 85。比較絕對數量時 Y 軸應從零開始,需要強調局部差異時也要明確標示軸範圍。
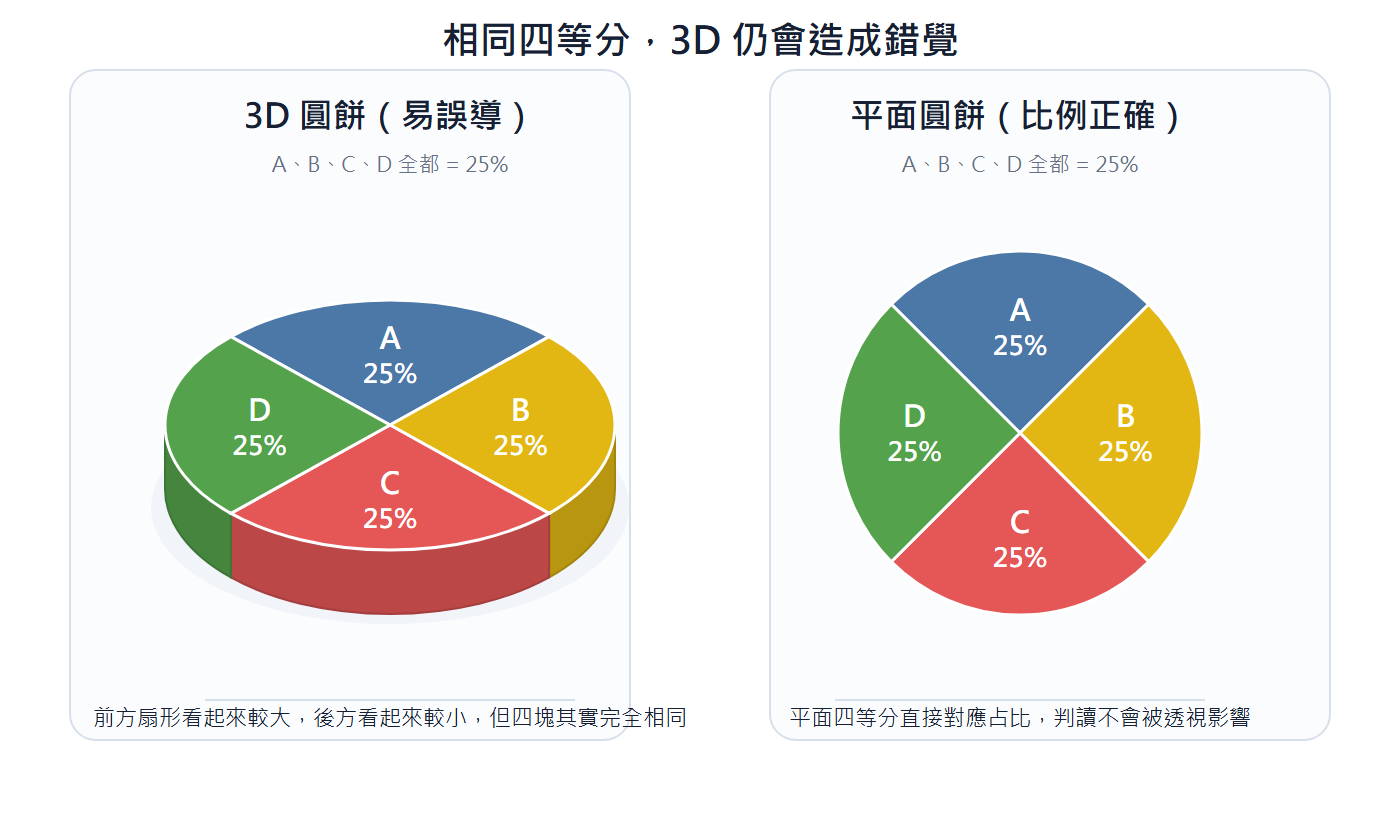
3D 圓餅圖:3D 透視會讓靠近前方的扇形因角度顯得比實際大、後方扇形被壓縮,導致比例判讀失真。要呈現占比,平面圓餅圖或長條圖比 3D 準確。
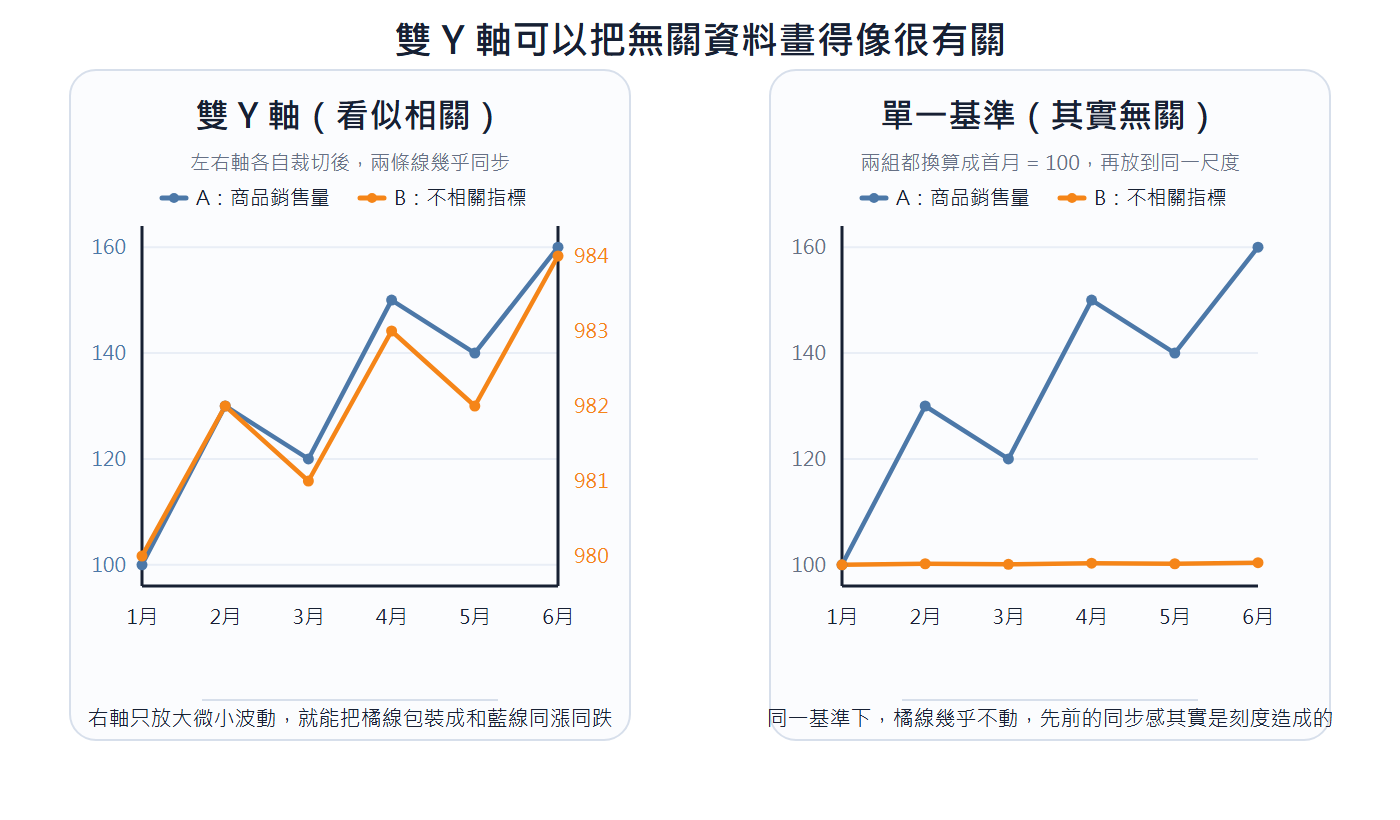
雙 Y 軸:把兩組資料分別掛在左右兩個 Y 軸上時,兩軸刻度可以各自調整。只要挑對刻度,就能讓兩條本來無關的線看起來同漲同跌,暗示出並不存在的關聯。要比較兩組數值,改用同一個基準才看得出真實關係。
資訊過載:一張圖塞太多系列或元素,會讓讀者抓不到重點。一張圖只講一件事。
敘述統計與常見統計觀念
資料分析通常先從敘述統計開始,了解資料的集中趨勢、離散程度與分布狀態,再進一步進行關聯分析與假設檢定。
| 指標 | 說明 | 特性 |
|---|---|---|
| 平均數 | 所有數值總和除以筆數。 | 容易受極端值影響。 |
| 中位數 | 排序後位於中間的值。 | 適合偏態分布或有極端值時參考。 |
| 眾數 | 出現次數最多的值。 | 類別資料也可使用。 |
| 標準差 | 衡量資料分散程度。 | 標準差越大,資料越分散。 |
| 四分位數 | 將排序資料切成四等分。 | 箱型圖常用 Q1、Q2、Q3。 |
| 相關係數 | 衡量線性關聯方向與強度。 | 沒有線性相關不代表沒有關係;有相關也不代表有因果。 |
常見統計與機率觀念:
- 條件機率:已知某事件發生時,另一事件發生的機率。
- 獨立事件:一事件發生不影響另一事件發生機率。
- 信賴區間:用區間估計母體參數可能所在範圍。
貝氏定理
條件機率的逆向應用,用新證據更新原本的機率判斷。一般條件機率回答「已知他是目標客群,他點擊廣告的機率」;貝氏定理回答反過來的問題,「已知他點擊了廣告,他是目標客群的機率」。實務上能直接觀察到的多半是後者的證據(點擊、購買、回訪),所以這個逆向推導才是行銷與顧客分析常用的方向。
用具體數字走一遍。假設目標客群只佔曝光人口的 10%,這支廣告對目標客群的點擊率是 60%、對其他人只有 5%。以每 1000 次曝光估算,期望點擊有 60 個來自目標客群(100 人 × 60%)、45 個來自其他人(900 人 × 5%),合計 105 個。在「已知某人點了廣告」的條件下,他是目標客群的機率就是 60 ÷ 105,約 57.1%。這個結果只取決於那三個比率(先驗 10% 與兩個點擊率),跟後台實際記錄到幾次點擊無關。
假設檢定、p 值與型一型二錯誤
假設檢定通常先立一個虛無假設,也就是「沒有差異、沒有效果」的保守立場,例如「新版網頁的轉換率和舊版一樣」,再看資料夠不夠推翻它。
假設新舊版本的轉換率真的沒有差異,卻出現眼前這麼大、甚至更大的差距,這種情況的發生機率就是 p 值。當 p 值低於事先設定的顯著水準(如 0.05),代表這結果低到不像「沒差異」時該有的樣子,因此推翻虛無假設。要注意 p 值不是「虛無假設為真的機率」,也不是效果的大小,這是兩個最常見的誤讀。
推翻與否都可能犯錯,分成兩型:
- 型一錯誤(偽陽性):虛無假設其實成立卻被推翻,把「沒效果」誤判成「有效果」。
- 型二錯誤(偽陰性):虛無假設其實不成立卻沒被推翻,把「有效果」誤判成「沒效果」。
而這條顯著水準的界線,本質上就是願意承受的型一錯誤機率上限。
t 檢定、F 檢定、卡方檢定
統計檢定就是用手上的樣本資料,判斷某個關於母體的假設是否成立;前面的虛無假設、p 值就是它共通的判斷邏輯。實際要用哪一種檢定,取決於資料型態與想比較的對象,常見的有以下三種。
| 檢定 | 比較/檢驗的對象 | 典型問題 |
|---|---|---|
| t 檢定 | 一到兩組的平均數 | 兩組顧客的平均客單價是否有差異? |
| F 檢定 | 兩組的變異數(資料的離散程度) | 兩條產線的品質波動是否一致? |
| 卡方檢定 | 兩個類別變數之間是否有關聯 | 性別與是否購買有沒有關聯? |
ANOVA 與 F 檢定
要比較三組以上的平均數(例如三家門市的平均營收是否相同),用的是變異數分析(Analysis of Variance, ANOVA),其檢定統計量就是 F 值。名稱叫「變異數分析」卻在比平均數,是因為它比較「組間變異」與「組內變異」,當組間差異明顯大於組內的隨機波動,就判定各組平均數不全相等。
經驗法則與柴比雪夫定理
兩者回答同一個問題,「平均數正負
- 經驗法則(Empirical Rule)只適用於近似常態(鐘形對稱)的資料。因為形狀已知,估計可以很精確,正負 1、2、3 個標準差內約涵蓋 68%、95%、99.7% 的資料。
- 柴比雪夫定理(Chebyshev's Theorem)不要求任何分布形狀。因為形狀不可控,只能給保守的下限,至少有
的資料落在平均數正負 個標準差內。
常見的 75% 就是把
所以同樣是正負 2 個標準差,資料近似常態時可以說「約 95%」;形狀不明或明顯偏態時,退而引用柴比雪夫說「至少 75%」。前者是形狀漂亮換來的精確估計,後者是不挑形狀換來的最低保證。
柴比雪夫定理的計算範例
定理可以正反兩個方向用。
已知幾個標準差,求最低比例:某工廠日產量平均 500 件、標準差 20 件,問 460 到 540 件至少涵蓋多少資料?460 與 540 距平均數都是 40 件,剛好是 2 個標準差(
已知要保證的比例,求區間:某配送中心平均配送 40 分鐘、標準差 8 分鐘,要保證至少 84% 的訂單落在對稱區間內,區間該多大?由
常態分布與偏態(Skewness)
資料分布的形狀會影響集中趨勢指標的選擇與分析方法。
| 分布類型 | 形狀 | 平均數、中位數、眾數關係 | 典型例子 |
|---|---|---|---|
| 對稱(常態分布) | 鐘形對稱 | 三者重合或極接近 | 身高、體重 |
| 右偏(正偏態) | 長尾在右、峰偏左 | 眾數 < 中位數 < 平均數 | 所得、房價、消費金額 |
| 左偏(負偏態) | 長尾在左、峰偏右 | 平均數 < 中位數 < 眾數 | 退休年齡、考試高分群 |
當資料明顯偏態時,平均數會被尾端極端值拉動,中位數通常是更具代表性的集中趨勢指標。
資料探勘與機器學習
資料探勘是從大量資料中找出模式、關聯與可支援決策的知識。常見方法包含決策樹、群集分析、關聯規則探勘與機器學習。
| 方法 | 重點 | 常見應用 |
|---|---|---|
| 決策樹 | 用一系列判斷條件進行分類或預測。 | 顧客流失預測、信用風險分類 |
| 群集分析 | 將相似資料分成群組。 | 市場區隔、顧客分群、產品組合 |
| 關聯規則探勘 | 找出項目之間常一起出現的關係。 | 購物籃分析、交叉銷售 |
| 迴歸模型 | 預測連續數值目標。 | 銷售額預測、需求預測 |
| 分類模型 | 預測離散類別目標。 | 是否流失、是否違約、是否購買 |
機器學習可分為三類。
| 類型 | 資料特徵 | 目標 | 範例 |
|---|---|---|---|
| 監督式學習 | 有標籤資料。 | 學出輸入到答案的對應。 | 分類、迴歸 |
| 非監督式學習 | 沒有人工標註答案。 | 探索資料中的潛在結構。 | 分群、降維、關聯探索 |
| 強化學習 | 透過行動與回饋學習。 | 找到能累積較佳報酬的策略。 | 動態定價、路徑規劃、資源調度 |

迴歸預測連續數值(如明日銷售額),分類預測離散類別(如顧客是否流失),兩者皆屬監督式學習,差別在於目標變數的型態。
資料切分與過度擬合
建立模型時通常將資料切分為三部分,避免模型「死背」訓練資料卻無法泛化到新資料。
| 切分 | 英文 | 用途 |
|---|---|---|
| 訓練集 | Training Set | 讓模型從中學習參數,約佔 60-70%。 |
| 驗證集 | Validation Set | 調整超參數、選擇模型版本,約佔 15-20%。 |
| 測試集 | Test Set | 最終評估泛化能力,僅用一次,約佔 15-20%。 |
| 現象 | 英文 | 特徵 | 對策 |
|---|---|---|---|
| 過度擬合 | Overfitting | 訓練集表現好、測試集表現差,模型死背雜訊。 | 正則化、簡化模型、增加資料、提前停止、交叉驗證。 |
| 欠擬合 | Underfitting | 訓練集與測試集表現都差,模型過於簡單。 | 增加特徵、提高模型複雜度、減少正則化。 |
交叉驗證(Cross-Validation) 把訓練資料切成 K 份,每次以其中 1 份當驗證、其餘 K-1 份當訓練,重複 K 次後平均成績,常見為 K=5 或 K=10。可在資料量有限時更穩健地估計模型表現。
迴歸模型評估指標
迴歸模型常用幾個指標衡量預測誤差,差別在於對「大誤差」的敏感度與是否好解讀。
| 指標 | 全稱 | 重點 |
|---|---|---|
| MAE | Mean Absolute Error,平均絕對誤差 | 誤差絕對值的平均,對每筆誤差一視同仁、較不受極端值影響。 |
| RMSE | Root Mean Squared Error,均方根誤差 | 誤差先平方再開根號,會放大大誤差,要嚴懲極端預測錯誤時用它。 |
| MAPE | Mean Absolute Percentage Error,平均絕對百分比誤差 | 以百分比表示誤差,可跨不同量級比較,但實際值接近 0 時會失真。 |
| R² | Coefficient of Determination,決定係數 | 模型對整體變異的解釋比例,看整體配適好壞,不是針對單筆誤差的懲罰。 |
分類模型評估指標
分類模型的評估從混淆矩陣(Confusion Matrix)出發,把預測結果分成四格,真陽性(TP)、偽陽性(FP)、真陰性(TN)、偽陰性(FN),再從中算出各指標。
| 指標 | 英文 | 算法 | 回答的問題 |
|---|---|---|---|
| 準確率 | Accuracy | (TP + TN) ÷ 全部 | 整體預測對了多少?類別不平衡時會失真。 |
| 精確率 | Precision | TP ÷ (TP + FP) | 預測為陽性的裡面,多少是真的陽性? |
| 召回率 | Recall | TP ÷ (TP + FN) | 實際為陽性的裡面,抓到了多少? |
| F1 分數 | F1 Score | 精確率與召回率的調和平均 | 兩者需兼顧時的綜合指標。 |
精確率與召回率通常互相拉扯,依錯誤成本取捨。例如詐騙偵測漏抓的代價高,偏重召回率;行銷名單誤發的成本低但會騷擾客戶,偏重精確率。
CRISP-DM 資料探勘標準流程
CRISP-DM(Cross Industry Standard Process for Data Mining)是業界廣泛採用的資料探勘方法論,包含六個階段,可視情況回溯至前一階段。

資料探勘流程方法論對照
除了 CRISP-DM,KDD(Knowledge Discovery in Databases,資料庫知識探索)與 SEMMA 也是常見的資料探勘流程。KDD 出現得更早、偏學術;SEMMA 由 SAS 提出,名稱取自 Sample、Explore、Modify、Model、Assess 五個階段的字首。三者目標相近,差別在階段切分與取向。
| 方法論 | 階段 | 取向 |
|---|---|---|
| CRISP-DM | 商業理解 → 資料理解 → 資料準備 → 模型建立 → 評估 → 部署 | 偏商業導向,起點是商業目標、終點是部署落地。 |
| KDD | 選擇 → 前處理 → 轉換 → 資料探勘 → 解釋與評估 | 偏資料技術視角,學術導向。 |
| SEMMA | 取樣 → 探索 → 修改 → 建模 → 評估 | 偏工具操作層,缺少商業理解與部署階段。 |
經營管理基本知識
企業經營環境與策略管理
企業必須評估環境,是因為組織策略、組織結構與市場績效都受環境影響。策略學者 Chandler 的聯結理論可簡化為「環境 → 策略 → 結構」。
| 觀點 | 說明 |
|---|---|
| 策略觀點 | 組織在草創、成長、成熟、衰退等階段採取不同策略。 |
| 市場觀點 | 組織將投入轉為產出,必須掌握市場才能生存與成長。 |
| 競爭觀點 | 企業須提供比競爭者更具吸引力的產出,並持續獲利。 |
企業環境可分為內部環境與外部環境。
| 類型 | 因子 |
|---|---|
| 內部環境 | 股東、董事會、組織文化、組織結構、員工態度與價值觀、管理程序與方法 |
| 特定環境 | 顧客群、供應商、競爭群、金融機構、股東群、政府、壓力團體 |
| 一般環境 | 經濟、政治與法律、社會文化、科技、人口結構、自然生態、國際化 |
PEST 與 PESTEL 分析
PEST/PESTEL 是分析一般環境的常用框架,從多個面向系統化盤點外部影響因素。
| 縮寫 | 構面 | 內容 |
|---|---|---|
| P | Political(政治) | 政府政策、政治穩定度、貿易協定。 |
| E | Economic(經濟) | GDP、利率、匯率、通膨、消費力。 |
| S | Social(社會) | 人口結構、文化、生活型態、教育水準。 |
| T | Technological(科技) | 技術趨勢、研發投入、自動化、智慧財產權。 |
| E | Environmental(環境) | 氣候變遷、永續法規、能源、污染(PESTEL 新增)。 |
| L | Legal(法律) | 勞動法、消費者保護、公平交易、產業法規(PESTEL 新增)。 |
PEST 為原始版本,PESTEL(也稱 PESTLE)額外加入環境與法律構面,因應永續發展與法規遵循議題日益重要。
競爭與策略分析框架
波特五力分析用來評估產業競爭壓力。五力均與企業特定環境有關。
| 五力 | 核心問題 | 這股力較強的情況 |
|---|---|---|
| 供應商議價能力 | 供應商能否提高價格或降低供應條件? | 供應商集中、替代來源少、轉換成本高、供應商可向前整合。 |
| 顧客議價能力 | 顧客能否壓低價格或要求更多服務? | 買方集中或採購量大、產品標準化、轉換成本低、買方可向後整合。 |
| 潛在進入者的威脅 | 新進者是否容易進入市場? | 進入障礙低,如規模經濟、品牌、資本、通路與法規門檻都不高。 |
| 替代品的威脅 | 其他產品或服務能否取代既有需求? | 替代品性價比高、顧客轉換成本低。 |
| 現有廠商間競爭 | 產業內競爭是否激烈? | 競爭者多且勢均力敵、產業成長趨緩、固定或退出障礙高、產品差異小。 |

圖中四個箭頭都指向中央的現有廠商間競爭,是因為另外四股力會影響產業內競爭的激烈程度。但現有廠商間競爭本身也是五力之一,五者是對等的壓力,真正由它們共同決定的是整個產業的競爭強度與獲利空間。
波特三大競爭策略
完成五力分析後,企業可依產業狀況選擇對應的競爭策略。
| 策略 | 英文 | 重點 | 適用情境 |
|---|---|---|---|
| 成本領導 | Cost Leadership | 在同等品質下提供最低成本,靠規模經濟與效率取勝。 | 大眾市場、價格敏感型顧客。 |
| 差異化 | Differentiation | 提供具獨特價值的產品或服務,顧客願意支付溢價。 | 品牌、設計、技術或服務具差異化潛力。 |
| 聚焦 | Focus | 鎖定特定區隔市場,在該區隔內採行成本或差異化策略。 | 利基市場、特定族群或地理區。 |
SWOT 分析用來盤點內外部條件。
| 類型 | 來源 | 說明 |
|---|---|---|
| Strengths(優勢) | 內部 | 組織具備的有利條件。 |
| Weaknesses(劣勢) | 內部 | 組織內部不足或限制。 |
| Opportunities(機會) | 外部 | 外部環境中的有利因素。 |
| Threats(威脅) | 外部 | 外部環境中的不利因素。 |
TOWS 矩陣(SWOT 的策略推導)
SWOT 只盤點現況,TOWS Matrix 進一步將內外部因素交叉,產出四種策略方向。
| 策略 | 組合 | 方向 |
|---|---|---|
| SO 策略(進攻) | 優勢 + 機會 | 用內部優勢把握外部機會。 |
| WO 策略(補強) | 劣勢 + 機會 | 補強內部弱點以掌握機會。 |
| ST 策略(防禦) | 優勢 + 威脅 | 用優勢化解外部威脅。 |
| WT 策略(撤退) | 劣勢 + 威脅 | 縮減、轉型或退出,避免雙重壓力。 |
BCG 矩陣用市場成長率與相對市場占有率分析事業單位。
| 類型 | 市場成長率 | 相對市場占有率 | 管理含義 |
|---|---|---|---|
| 明星 | 高 | 高 | 需要投資維持成長。 |
| 金牛 | 低 | 高 | 成熟期、現金流穩定。 |
| 問題 | 高 | 低 | 需評估是否加碼投資擴大市占率,否則放棄退出。 |
| 狗 | 低 | 低 | 通常需縮減、轉型或退出。 |

Ansoff 成長矩陣
Ansoff Matrix 從「產品」與「市場」兩個維度的新舊組合,推導四種成長策略。
| 策略 | 產品 × 市場 | 說明 |
|---|---|---|
| 市場滲透 | 既有產品 × 既有市場 | 提高現有顧客購買頻率或市占率。 |
| 市場開發 | 既有產品 × 新市場 | 將既有產品拓展到新地區或新客群。 |
| 產品開發 | 新產品 × 既有市場 | 對現有顧客推出新產品或新功能。 |
| 多角化 | 新產品 × 新市場 | 風險最高,跨足新領域。 |
製造業與服務業
| 面向 | 製造業 | 服務業 |
|---|---|---|
| 產出 | 有形產品。 | 無形服務。 |
| 管理重點 | 成本、品質、客製化與生產效率。 | 顧客體驗、流程品質與服務一致性。 |
| 品質認定 | 較容易用客觀規格量測。 | 常受互動情境與顧客主觀感受影響。 |
| 顧客參與 | 多數產品生產時顧客不在場。 | 服務提供與消費常同時發生。 |
服務業常見四個特性:
- 無形性(Intangibility):服務無法像實體產品一樣觸摸。
- 不可分割性(Inseparability):服務提供與消費常同時發生。
- 易變性(Variability):服務品質受人員、顧客與情境影響。
- 易消逝性(Perishability):未被使用的服務產能無法儲存。
行銷與產品管理
行銷是為了創造交換價值、滿足顧客需求並支持企業獲利。常見主題包含行銷組合、消費者行為、購買程序、市場區隔與產品生命週期。
行銷組合 4Ps
| 4P | 說明 |
|---|---|
| Product(產品) | 提供給顧客的商品、服務、品牌與附加價值。 |
| Price(價格) | 定價策略、折扣與付款條件。 |
| Place(通路) | 產品如何到達顧客。 |
| Promotion(推廣) | 廣告、促銷、公關與銷售溝通。 |
4Ps 對應 4Cs(顧客視角)
4Ps 為企業視角,4Cs 由 Robert Lauterborn 提出,從顧客角度重新詮釋行銷組合。
| 4P | 4C | 觀點轉換 |
|---|---|---|
| Product(產品) | Customer(顧客價值) | 從「我們做什麼產品」轉為「顧客需要什麼價值」。 |
| Price(價格) | Cost(顧客成本) | 從「定價多少」轉為「顧客付出的總成本」。 |
| Place(通路) | Convenience(便利性) | 從「鋪貨在哪」轉為「顧客取得是否便利」。 |
| Promotion(推廣) | Communication(溝通) | 從「單向廣告」轉為「雙向溝通」。 |
STP 行銷策略
STP 是行銷策略的核心流程,連接市場分析與行銷組合設計。
| 步驟 | 英文 | 說明 |
|---|---|---|
| 市場區隔 | Segmentation | 依地理、人口、心理、行為等變數將市場切分為不同區隔。 |
| 目標市場 | Targeting | 從區隔中選擇企業欲服務的目標客群。 |
| 市場定位 | Positioning | 在目標客群心中建立差異化的品牌印象與價值主張。 |
購買者決定消費程序
- 需求產生。
- 資訊蒐集。
- 評估需求方案。
- 決定購買。
- 買後使用滿意度評估。
購買決策影響因素
消費者購買決策受多層面因素影響,行銷策略需依目標客群的主導因素設計。
| 層面 | 因素 |
|---|---|
| 文化因素 | 文化、次文化、社會階層。 |
| 社會因素 | 參考群體、家庭、角色與地位。 |
| 個人因素 | 年齡、職業、經濟狀況、生活型態、人格。 |
| 心理因素 | 動機、知覺、學習、信念與態度。 |
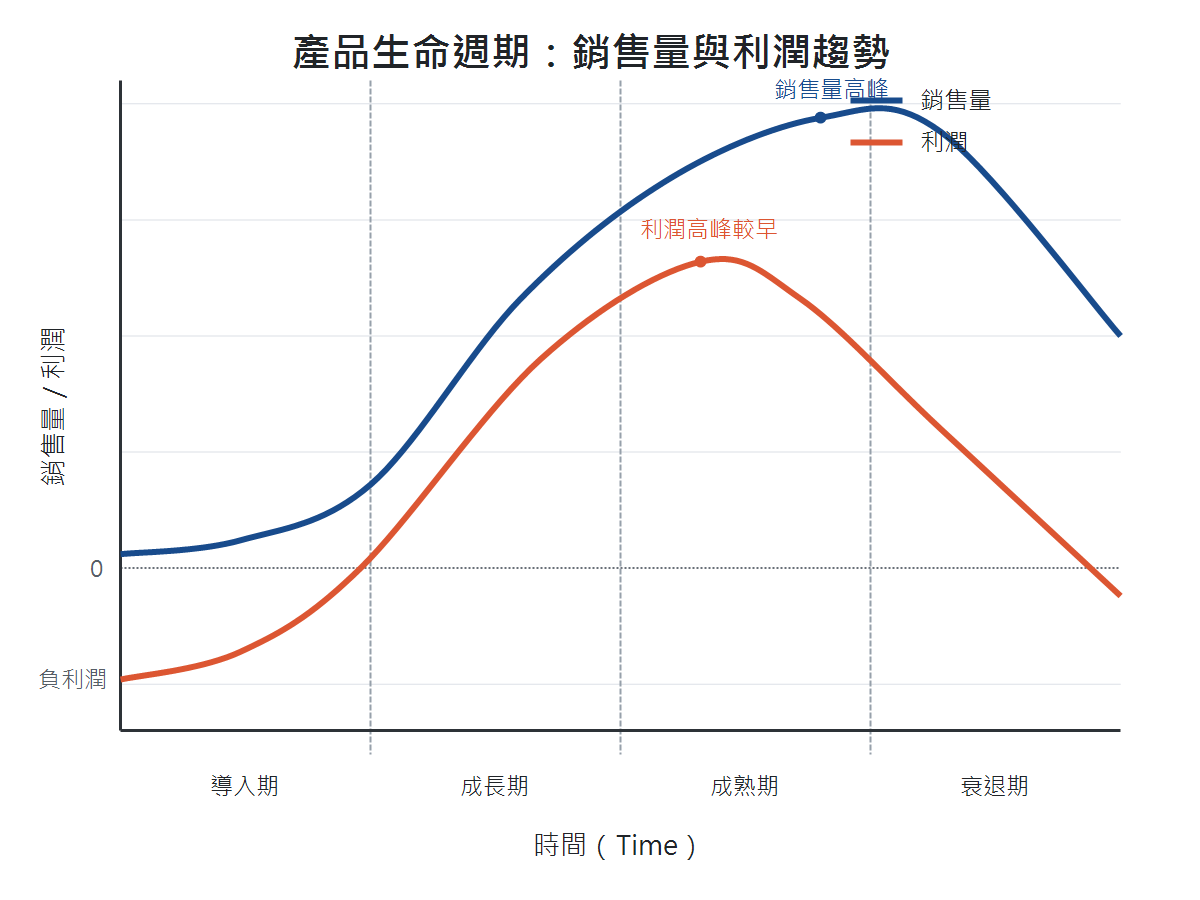
產品生命週期
| 階段 | 特徵 | 管理重點 |
|---|---|---|
| 導入期 | 市場接受度仍低,銷售量有限。 | 建立認知、降低進入障礙。 |
| 成長期 | 銷售量快速增加,新使用者加入,利潤同步攀升。 | 擴大市場、增加市占率。 |
| 成熟期 | 市場穩定、銷量達高峰,但競爭加劇,利潤已過高峰、開始下滑。 | 控制成本、差異化、維持現金流。 |
| 衰退期 | 需求下降,產品可能被替代。 | 決定淘汰、轉型或維持利基市場。 |
把四個階段的銷售量與利潤畫成曲線,可以看出利潤的高峰通常早於銷售量的高峰。成長期後段競爭還不激烈、成本已隨規模擴大而下降,利潤先衝到頂;進入成熟期後,銷售量雖攀升到最高,但競爭加劇、價格與毛利下滑,利潤已開始回落。
產品擴散:創新接受者類型(Rogers' Diffusion of Innovations)
Everett Rogers 將消費者依採用新產品的時間先後分為五類,呈常態分布。
| 類型 | 英文 | 占比 | 特性 |
|---|---|---|---|
| 創新者 | Innovators | 2.5% | 願意嘗試新事物、容忍高風險與不完美。 |
| 早期採用者 | Early Adopters | 13.5% | 意見領袖,影響後續族群採用決策。 |
| 早期大眾 | Early Majority | 34% | 經深思後採用,重視實用與口碑。 |
| 晚期大眾 | Late Majority | 34% | 多在多數人採用後才跟進,較保守。 |
| 落後者 | Laggards | 16% | 傳統導向,最後才接受或拒絕採用。 |
研究發展與人力資源
研究發展(R&D)是企業維持創新與競爭力的重要活動,包含研究與發展兩大面向。
| 類型 | 說明 |
|---|---|
| 基礎研究 | 發展與驗證理論,結果可能有或沒有實務應用價值。 |
| 應用研究 | 將基礎研究成果轉向具體應用與問題解決。 |
| 發展與工程設計 | 將知識與研究結果系統化應用於產品或服務。 |
| 試驗性生產 | 少量試作,確認設計、模具、物料、品質與配送問題。 |
R&D 具有非例行性與高度風險。投入資源不保證產生專利、產品或市場成功,還需要面對量產、行銷、通路與顧客接受度的考驗。
人力資源管理則包含招募甄選、訓練發展、人力異動、績效評估、獎勵與人力留任等活動。
| 活動 | 重點 |
|---|---|
| 人力資源規劃 | 了解現有人力供給、評估未來需求、規劃供需落差。 |
| 甄選 | 透過履歷、面談、筆試、背景調查找出合適人選。 |
| 員工培育訓練 | 激發自我學習、實務導向、員工參與、即時回饋。 |
| 績效評估 | 找出績效問題、後果與改善方案。 |
| 薪資福利 | 包含金錢報酬與非金錢報酬。 |
會計、財務與財務指標
會計與財務管理的差異在於時間觀點與工作重點。
| 項目 | 會計 | 財務管理 |
|---|---|---|
| 時間觀點 | 偏歷史資訊整理與報告。 | 偏未來資金規劃與金融決策。 |
| 工作重點 | 記錄、彙整、報告交易活動。 | 投資、融資、資金運用與風險管理。 |
| 使用者 | 內部管理者與外部資訊使用者。 | 管理者、投資者、債權人等。 |
| 指標 | 類型 | 說明 |
|---|---|---|
| 邊際利潤率 | 獲利能力 | 衡量每單位銷售留下多少利潤。 |
| 投資報酬率(ROI) | 獲利能力 | 衡量投資帶來的報酬。 |
| 每股盈餘(EPS) | 獲利能力 | 每股普通股對應盈餘。 |
| 流動比率 | 清償能力 | 衡量短期償債能力,不是獲利率指標。 |
| 存貨週轉率 | 營運效率 | 衡量存貨轉換速度。 |
EOQ 經濟訂購量公式
設年度需求量
EOQ 是使「訂購成本」與「持有成本」總和最低的單次訂購量,前提是需求穩定、前置時間固定、補貨即時。
管理活動與組織
管理是管理者運用組織資源達成目標的過程。
達成目標與運用資源,正好對應衡量管理表現的兩個面向:
- 效能(Effectiveness):目標是否合宜,是否達成該做的事。
- 效率(Efficiency):投入與產出的關係,是否用較少資源達成結果。
管理者依層級可分為第一線管理者、中階管理者與高階管理者。

不同層級所需的技能比例不同。第一線管理者偏重技術性技能,高階管理者偏重概念性技能,人際性技能在各層級皆重要。
| 管理者技能 | 說明 | 常見於 |
|---|---|---|
| 技術性技能 | 使用專業知識執行工作。 | 第一線管理者較需要。 |
| 人際性技能 | 溝通、合作、激勵與領導。 | 各層級都需要。 |
| 概念性技能 | 分析問題、評估方案、規劃行動。 | 高階管理者較需要。 |
| 政治性技能 | 建立權勢基礎與利益連結。 | 涉及跨部門協調時重要。 |
Mintzberg 管理者角色可分為三類。
| 類型 | 角色 |
|---|---|
| 人際性角色 | 頭臉人物、領導者、連絡者 |
| 資訊性角色 | 監控者、傳播者、發言人 |
| 決策性角色 | 企業家、清道夫、資源分配者、協商者 |
企業管理四大功能:
| 功能 | 說明 |
|---|---|
| 規劃(Planning) | 界定目標、擬定策略與計畫。 |
| 組織(Organizing) | 分派資源、安排工作與建立責任關係。 |
| 領導(Leading) | 激勵、溝通、協調與處理衝突。 |
| 控制(Controlling) | 監督績效、比較目標與實際落差、採取修正措施。 |
PDCA 循環(Deming Cycle)
PDCA 是品質管理與持續改善的基礎循環,由 Walter Shewhart 提出、W. Edwards Deming 推廣,常被視為管理四大功能的執行模式。

| 階段 | 對應管理功能 | 重點 |
|---|---|---|
| Plan | 規劃 | 界定問題、設定目標、擬定行動方案。 |
| Do | 組織 + 領導 | 依計畫執行,記錄過程與資料。 |
| Check | 控制 | 評估成效、找出與目標的落差。 |
| Act | 控制 + 規劃 | 成功則標準化、不成功則修正後重啟循環。 |
延伸版本 PDSA(Plan-Do-Study-Act)以「研究(Study)」取代「檢核(Check)」,強調深入分析而非單純檢核。Six Sigma 的 DMAIC(Define 定義、Measure 衡量、Analyze 分析、Improve 改善、Control 控制)則是更聚焦於品質改善專案的進階版本。
數位化企業資訊工具基本知識
數位化企業與數位轉型
數位化企業是能運用數位科技與資訊網路,與客戶、供應商、商業夥伴進行溝通協作、電子交易、資料共享與流程改造的企業。數位轉型的重點不只是導入工具,而是改變營運流程、服務交付方式與價值創造模式。

營運智慧資訊技術
| 技術 | 重點 | 營運智慧應用 |
|---|---|---|
| AI | 透過機器學習、深度學習與 NLP 支援分析與決策。 | 顧客行為預測、庫存風險分析、社群輿情解析。 |
| 生成式 AI | 以大型語言模型(LLM)與擴散模型自動生成文字、圖像、程式碼。 | 行銷文案、客服對話、報表摘要、SQL 自動產生、知識問答。 |
| 雲端運算 | 透過網路按需取得運算、儲存與平台資源。 | 擴充資料平台、降低尖峰資源採購壓力。 |
| RFID | 透過射頻訊號追蹤與辨識物件。 | 物料追蹤、庫存盤點、配送中心自動入出庫。 |
| IoT | 將感測器、設備與網路連接。 | 設備監控、智慧物流、智慧農業、環境監測。 |
| 大數據 | 處理高量、高速、多樣且不確定的資料。 | 行銷分析、生產風險分析、顧客洞察。 |
大數據 5V 特性
| V | 中文 | 說明 |
|---|---|---|
| Volume | 量大 | 資料量達 TB、PB 等級。 |
| Velocity | 速度快 | 高頻產生與處理需求。 |
| Variety | 多樣性 | 結構化、半結構化、非結構化並存。 |
| Veracity | 真實性 | 資料品質與可信度不一。 |
| Value | 價值 | 巨量資料中找出能轉化為商業決策的部分。 |
iPAS 官方學習指引在大數據特性處列的是 4V(Volume、Velocity、Variety、Veracity);Value 是其他教材常見的擴充,合起來稱 5V。
AI / ML / DL / GenAI 範圍關係

圖為簡化的範圍包含關係。ML 是 AI 的子集、DL 是 ML 的子集,目前主流的 GenAI 也以深度學習實作。
NIST 定義的標準雲端服務模式有三種,分別是 IaaS、PaaS 與 SaaS;下表也一併列出常見於 serverless 架構的 FaaS,它並非 NIST 三大標準之一。
| 服務模型 | 全名 | 供應商管理範圍 | 客戶管理範圍 | 典型服務 |
|---|---|---|---|---|
| IaaS | Infrastructure as a Service(基礎設施即服務) | 實體機、網路、儲存、虛擬化 | OS、中介軟體、執行環境、應用程式、資料 | AWS EC2、Azure VM、GCP Compute Engine |
| PaaS | Platform as a Service(平台即服務) | IaaS 範圍 + OS、中介軟體、執行環境 | 應用程式、資料 | Heroku、Azure App Service、AWS Elastic Beanstalk |
| FaaS | Function as a Service(函式即服務) | PaaS 範圍 + 執行環境管理、自動擴展 | 函式程式碼、觸發設定 | AWS Lambda、Azure Functions、GCP Cloud Functions |
| SaaS | Software as a Service(軟體即服務) | PaaS 範圍 + 應用程式 | 資料(使用者操作層面) | Gmail、Microsoft 365、Salesforce |
NIST 另定義了四種部署模式,描述雲端基礎設施為誰所用:
| 部署模式 | 說明 |
|---|---|
| 公有雲(Public Cloud) | 由雲端服務商營運,開放一般大眾租用,多租戶共用資源。 |
| 私有雲(Private Cloud) | 專供單一組織使用,可自建或委外代管,控制權與隔離性最高。 |
| 社群雲(Community Cloud) | 由有共同需求(如法規、安全)的多個組織共用。 |
| 混合雲(Hybrid Cloud) | 組合兩種以上部署模式,如平時用私有雲、尖峰擴充到公有雲。 |
RFID 系統包含電子標籤、讀卡機與應用系統。電子標籤又分為主動式與被動式:
| 類型 | 電力來源 | 特性 |
|---|---|---|
| 主動式 RFID | 內建電池。 | 可主動傳送資料,感應範圍較大。 |
| 被動式 RFID | 無內建電池。 | 接收讀卡機訊號後以電磁感應產生電流,感應範圍較小。 |
物聯網三層架構:
| 層級 | 說明 |
|---|---|
| 感測器層 | 將具感測、辨識、通訊能力的元件嵌入物體。 |
| 網路層 | 透過有線或無線傳輸接收資訊並進行處理。 |
| 應用層 | 將資料與產業場景結合,提供特定服務。 |

資訊系統的組織層級
企業資訊系統可依服務的組織層級分類,從基層日常交易到高層策略決策,形成金字塔結構。越往上層,資料越彙總、面對的決策越非結構化。

| 系統 | 中文 | 英文全名 | 服務層級 | 重點 |
|---|---|---|---|---|
| TPS | 交易處理系統 | Transaction Processing System | 作業層 | 記錄與處理日常營運交易,如訂單、出貨、請款、薪資。 |
| MIS | 管理資訊系統 | Management Information System | 管理層 | 彙總 TPS 的交易資料,產生例行性管理報表與摘要。 |
| DSS | 決策支援系統 | Decision Support System | 管理層 | 以互動式模型與分析工具支援半結構化決策。 |
| EIS | 主管資訊系統 | Executive Information System | 策略層 | 整合內外部資訊,以儀表板支援高層策略決策(亦稱 ESS)。 |
| ES | 專家系統 | Expert System | 跨層 | 將特定領域專家知識整理成規則庫,輔助判斷與診斷。 |
結構化、半結構化與非結構化決策
決策依「有沒有明確的處理程序」分三種,這也是資訊系統分層的依據:
- 結構化決策:有明確規則與步驟、可重複,甚至能自動化,如庫存補貨、薪資計算。多由 TPS/MIS 處理。
- 半結構化決策:部分有規則、部分需人為判斷,如預算編列、行銷資源分配。是 DSS 的主場。
- 非結構化決策:問題新穎、沒有現成程序,高度倚賴經驗判斷,如新事業投資、併購。多落在策略層的 EIS。
越往金字塔上層,決策越偏非結構化。
TPS 是其他系統的資料基礎,MIS 與 DSS 都仰賴 TPS 累積的交易資料。MIS 與 DSS 的差別在於前者產生固定格式的例行報表、回答「發生了什麼」,後者透過模型進行互動分析、回答「如果這樣做會如何」。下一節的 ERP、CRM、SCM 等功能型系統則橫跨多個層級,內部同時包含交易處理與報表分析能力。
數位化企業常見資訊系統
| 系統 | 中文 | 英文全名 | 核心用途 |
|---|---|---|---|
| ERP | 企業資源規劃 | Enterprise Resource Planning | 整合企業內部財務、製造、生產、銷售、人資等流程與資料。 |
| MRP | 物料需求規劃 | Material Requirements Planning | 依生產排程與物料清單計算原物料的採購與生產需求。 |
| MES | 製造執行系統 | Manufacturing Execution System | 連接生產排程與現場設備,即時掌握工單、產量與品質。 |
| PLM | 產品生命週期管理 | Product Lifecycle Management | 管理產品從設計、研發、量產到汰除的資料與流程。 |
| SCM | 供應鏈管理 | Supply Chain Management | 管理供應鏈上下游規劃與執行。 |
| CRM | 客戶關係管理 | Customer Relationship Management | 管理客戶資料、互動、銷售管道與服務紀錄。 |
| EC | 電子商務 | Electronic Commerce | 支援電子化交易、資訊分享與關係維持。 |
| KM | 知識管理 | Knowledge Management | 支援組織知識的儲存、檢索、創造、移轉與應用。 |
| BI | 商業智慧 | Business Intelligence | 蒐集、整合、分析與呈現資料,支援決策。 |
| RPA | 機器人流程自動化 | Robotic Process Automation | 用軟體機器人自動執行規則明確且重複性高的任務。 |
| HRIS | 人力資源資訊系統 | Human Resource Information System | 管理招募、出勤、薪資、考核與人力資料。 |
ERP
ERP 是財務會計導向的整合資訊系統,用於規劃、控制與整合企業從接單、製造、運送到結算報表的資源與資訊。它通常由整合軟體模組與集中式資料庫組成。
常見 ERP 模組包含:
- 財務會計。
- 人力資源。
- 製造與生產。
- 業務與行銷。
- 採購與庫存。
- 供應鏈管理。
製造資訊系統:MRP、MES 與 PLM
製造領域有幾個常一起出現的資訊系統,彼此分工協作。ERP 由 MRP 演進而來(MRP → MRP II → ERP);MES 與 PLM 則是與 ERP 串接的互補系統,分別聚焦現場執行與產品/工程資料管理。
| 系統 | 定位 | 與 ERP 的關係 |
|---|---|---|
| MRP(物料需求規劃) | 依主生產排程與物料清單(BOM)推算物料採購與生產時程。 | ERP 的前身,後擴充為涵蓋產能與財務的 MRP II,再演進為 ERP。 |
| MES(製造執行系統) | 銜接 ERP 的生產計畫與現場設備,即時回報工單進度、產量與品質。 | 補上 ERP 與現場機台之間的執行落差,並向 ERP 回拋實際生產資料。 |
| PLM(產品生命週期管理) | 管理產品從設計、研發、量產到汰除的工程資料與流程。 | 提供產品主檔與 BOM(物料清單)來源,供 ERP 與 MES 引用。 |
MRP 解決「何時該備多少料」,MES 解決「現場實際做得如何」,PLM 解決「產品本身的資料怎麼管」。三者與 ERP 串接後,構成製造業從接單、備料、生產到出貨的完整資訊鏈。
「前身」是被吸收,不是取代
在資訊系統裡說 MRP 是 ERP 的「前身」,指的是 MRP 的功能被涵蓋面更廣的 ERP 吸收、成為其中一個模組,而不是 MRP 被另一套系統取代後消失。所以 ERP 本身就含有 MRP 的算料功能,市面上幾乎看不到獨立的 MRP 系統。
MES 與 PLM 則會和 ERP 並存,因為三者負責的範圍與層次不同、各司其職,靠介面交換資料而非互相取代。所以 ERP 與 MRP 是「包含」關係,ERP 與 MES、PLM 是「拍檔」關係。
SCM
供應鏈包含產品或服務從原物料到交付顧客過程中的供應商、製造商、零售商與物流等參與者。
SCM 系統可分為供應鏈規劃與供應鏈執行:
- 供應鏈規劃:需求預測、物料需求、生產計畫、物流配送規劃。
- 供應鏈執行:管理產品從配銷中心到倉儲與顧客端的流動。
供應鏈依「生產由什麼觸發」可分為三種:
| 類型 | 生產觸發 | 取捨 |
|---|---|---|
| 推式(Push) | 依需求預測先生產,再鋪到通路。 | 庫存備妥、出貨快,但預測失準會造成過剩或缺貨。 |
| 拉式(Pull) | 收到實際訂單才生產或組裝。 | 庫存低、不會過量,但顧客等待的前置時間較長。 |
| 推拉式(Push-Pull) | 前段依預測推、後段依訂單拉。 | 兼顧推式的效率與拉式的彈性。 |
推拉式的關鍵是「推拉分界點」。分界點之前依預測把共用的零件或半成品先備好(推),收到訂單後再依顧客規格做最後的組裝或客製(拉)。例如電腦廠先備妥標準零件,接到訂單再依配置組裝,前段享規模效率、後段保留客製彈性。
電子商務
電子商務是透過資通訊科技支援買賣雙方資訊分享、交易執行與關係維持的商業活動。
| 型態 | 全稱 | 說明 |
|---|---|---|
| B2B | Business to Business | 企業對企業,買賣雙方都是企業,如企業與供應商間的採購平台、原物料交易平台。 |
| B2C | Business to Consumer | 企業直接把商品或服務賣給消費者,如網路書店、品牌官方電商。 |
| C2B | Consumer to Business | 消費者主導、企業回應,如團購集結議價、消費者發起需求由企業承接。 |
| C2C | Consumer to Consumer | 消費者之間交易、平台居中媒合,如拍賣網站、二手交易平台。 |
| B2E | Business to Employee | 企業透過內部平台對員工提供服務、資訊與商品,如員工入口網站、員工福利或購物平台、線上教育訓練。 |
| O2O | Online to Offline | 線上引流或下單、線下消費或取貨,如線上優惠券到實體店使用、餐飲外送與訂位。 |
電子商務趨勢包含社群化、行動化與在地化。行動裝置定位功能讓服務供應商可提供更貼近情境的位置服務。
KM
知識管理系統用資訊科技支援組織知識的儲存、檢索、創造、移轉與應用。
| 元件 | 說明 |
|---|---|
| 知識庫 | 文件庫與資訊庫,支援擷取、組織、儲存、搜尋與存取知識。 |
| 知識地圖 | 以圖形呈現知識來源、儲存位置、專家位置、任務與知識關係。 |
兩者分工不同。知識庫是存放知識的內容倉庫,知識地圖則是找知識的索引,標出知識散落在哪、由誰持有,並指向知識庫與其他來源(含人員腦中的隱性知識)。
知識地圖依組織知識的方式分三種:
| 類型 | 以什麼組織知識 |
|---|---|
| 概念性知識地圖 | 以概念或主題分類,呈現知識的層級與概念間關係。 |
| 流程性知識地圖 | 對應企業流程,標出各流程活動需要或產出哪些知識。 |
| 能力性知識地圖 | 對應人員能力,呈現專家所在與組織的知識能力分布。 |
BI
BI 蒐集、整合、分析並呈現企業資料以支援決策,運作機制可分為三個層面:
- 資料整合與清理:彙整 ERP、CRM、外部資料等來源,並進行標準化。
- 多維度分析與視覺化:將資料轉為圖表、儀表板或互動式報表。
- 即時監控與決策支援:提供警示、情境模擬與 KPI 追蹤。
CRM
CRM 以客戶為中心,整合行銷、銷售與服務的資料與流程,主要功能分三類:
- 資料整合與管理:集中整合客戶聯絡資訊、購買紀錄、服務紀錄與互動歷程。
- 行銷與銷售支持:管理潛在客戶、銷售管道與行銷自動化。
- 服務與互動管理:記錄客服互動、提供知識庫與自動化回覆。
CRM 的三種類型
| 類型 | 重點 |
|---|---|
| 營運型(Operational) | 自動化第一線的行銷、銷售與服務流程,直接面對客戶。 |
| 分析型(Analytical) | 分析營運型蒐集的客戶資料,做分群、價值評估與行為預測。 |
| 協同型(Collaborative) | 整合電話、網路、email 等多通路的客戶互動與溝通。 |
客戶終身價值(LTV)
客戶終身價值(Customer Lifetime Value, LTV)估算一位客戶在整段往來期間能帶來的總利潤,是分析型 CRM 衡量客戶價值的核心指標。在訂閱制的簡化模型下,LTV = 每月邊際利潤 × 預期存續月數,其中預期存續月數可用月流失率(Churn Rate)的倒數估算(1 ÷ 月流失率)。
LTV 計算範例
某 SaaS 服務每位訂戶每月平均收入(ARPU)30 美元、邊際毛利率 80%、月流失率 4%。預期存續月數為 1 ÷ 0.04 = 25 個月,每月邊際利潤為 30 × 80% = 24 美元,因此 LTV = 24 × 25 = 600 美元。
RPA
RPA 以軟體機器人模擬人工在系統介面上的操作,自動執行規則明確且重複性高的工作。適合資料輸入、檔案搬移、報表產生、系統間資料轉換等任務。它不等同 AI,但可與 AI 結合,處理更複雜的文件辨識與判斷流程。
數位化轉型與價值創造
商業模式(Business Model, BM)描述企業如何建立與使用資源,提供有價值的產品或服務給客戶,並藉此取得利潤與創造企業價值。
| 構面 | 說明 | 要素 |
|---|---|---|
| 價值主張 | 企業對目標客群提出的價值承諾。 | 目標客群、產品或服務、顧客價值 |
| 價值組態 | 企業內外部資源如何形成價值創造流程。 | 利害關係人網路、關鍵活動、顧客關係、配銷通路 |
| 價值結構 | 支撐商業模式的組織、技術與能力。 | 組織結構、組織文化、資通訊科技、核心資源、核心能力 |
| 價值財務 | 成本、定價、營收與獲利邏輯。 | 成本結構、定價模式、營收結構、潛在獲利 |
企業價值鏈(Value Chain)是企業從原料取得到產品或服務交付顧客的活動組合。波特價值鏈將活動分為主要活動與支援活動。
| 類型 | 定義 | 包含的活動 |
|---|---|---|
| 主要活動 | 直接參與產品或服務的生產與交付,沿流程一環接一環為產品累加價值。 | 內部物流、營運與生產加工、外部物流、行銷與銷售、售後服務 |
| 支援活動 | 不直接生產產品,而是橫跨並支撐所有主要活動,提供其所需的資源與基礎。 | 採購、人力資源管理、技術開發、企業基礎設施 |
簡單說,主要活動是產品從進料到售後的直線流程,支援活動則是橫向撐起這條流程的共同基礎。下圖中主要活動由左到右串接,支援活動橫跨其上,正是這個結構。

BPR 企業流程再造
企業流程再造(Business Process Re-engineering, BPR)是重新思考企業根本基礎,徹底翻新作業流程,使關鍵績效指標獲得大幅改善。
BPR 四個重點:
| 重點 | 說明 |
|---|---|
| 根本(Fundamental) | 重新詢問企業為什麼做這件事、為什麼這樣做。 |
| 徹底(Radical) | 從根本重新設計流程,不被既有規則限制。 |
| 大幅度(Dramatic) | 追求明顯改善,不只是小幅度漸進改善。 |
| 流程(Process) | 把焦點放在跨部門作業流程,而不只看組織結構。 |
學者 Davenport 與 Short 提出的五步驟模型:
- 建立企業願景及活動目的。
- 確定需要重新設計的流程。
- 瞭解現行流程。
- 確定資訊科技的功用。
- 建立新流程的雛型。
Gunasekaran 等學者提出的八步驟模型:
- 教導員工認識 BPR。
- 挑選及成立 BPR 推動團隊。
- 評估現行流程及初步確立需要再造的流程。
- 決定衡量方式。
- 設計再造流程。
- 教育訓練。
- 模擬測試。
- 正式導入新流程。
變革管理:Lewin 三階段模型
BPR 等大幅變革要能成功落地,需配套變革管理。Kurt Lewin 提出最經典的三階段變革模型。
| 階段 | 英文 | 重點 |
|---|---|---|
| 解凍 | Unfreezing | 建立變革急迫感、打破現狀慣性、減少員工抗拒。 |
| 改變 | Changing(Moving) | 推動新流程、新做法,期間提供訓練與支持。 |
| 再凍結 | Refreezing | 將新做法制度化、納入績效評估、形成新慣例。 |
Kotter 八步驟變革模型 為較具體的落地版本:
- 建立急迫感。
- 組成變革推動聯盟。
- 提出變革願景與策略。
- 溝通變革願景。
- 授權員工採取行動。
- 創造短期勝利。
- 鞏固成果並推動更多變革。
- 將新做法植入組織文化。
異動歷程
- 初版文件建立。